Ich wurde kürzlich mit der Idee konfrontiert, Digitalisierung ohne Mathematik zu unterrichten. Die Meinung war: weil Mathematik so schwierig ist, sollte man den überforderten Studierenden nur die nicht-mathematischen Digital Skills beibringen. Also Data Science ohne Statistik, Optimierung der Entscheidungsprozesse im Alltag ohne Wahrscheinlichkeitstheorie, künstlich intelligente Roboter ohne Algorithmen, Cybersecurity ohne Verschlüsselung und zwangsläufig: Finanzwirtschaft, die dem emotionalen Fühlen folgt und nicht den Zahlen.
Die Idee einer Digitalisierung, die sich an sozialen Werten orientiert, ist faszinierend und wurde auch am Swiss Digital Summit 2018 (am 27. September an der ETH in Zürich) diskutiert. Nur auch dort war klar: gerade wenn es um gesellschaftliche Werte geht, braucht es viel Mathematik. Ohne Mathematik keine digitale Aufklärung.
Meine Aufzählung der skurrilen Konsequenzen einer Digitalisierung ohne Mathematik enthält einen scheinbar nicht ganz überzeugenden Punkt: die algorithmenfreien künstlich intelligenten Roboter. Eine Zeitlang war in Teilen der KI-Community die Idee populär, dass die Intelligenz im Material liege. Das war eine kluge Idee: Man kann gutes Engineering einsetzen, um den Rechenbedarf von Computer massiv zu reduzieren. Das Ergebnis guten Engineerings hat Anteil an der resultierenden sensomotorischen Intelligenz. Der Grund ist simpel, Ingenieure arbeiten mit viel Mathematik.
Um eine lange Geschichte kurz zu machen: Mathematik ist zentral für die Digitalisierung. Nur dass es sich dabei meist nicht um die klassische Mathematik mit Papier und Bleistift handelt, sondern um eine Kombination von Denken in mathematischen Modellen und Rechnen mit mathematikbasierten Software-Werkzeugen.
Schlimmer noch: Es ist eine Illusion, zu hoffen, dass die mühsame Mathematik mit Papier und Bleistift gänzlich überflüssig werden wird. Sie ist fast zwingend notwendig, um jene Präzision des Denkens zu entwickeln, die man braucht, um beispielsweise mit Blockchains wirklich coole Dinge zu tun. Smart Contracts zu nutzen, ohne sie zu verstehen, das ist wie einen Vertrag zu unterschreiben, der in einer Sprache abgefasst ist, die man nicht beherrscht.
Durch den Verzicht auf Mathematikunterricht nimmt man jungen Menschen weitgehend die Chance, bei der Digitalisierung mithalten zu können. Man «disabled» sie. Das kann nicht unser Ziel sein! Darum müssen wir als Gesellschaft die weit verbreitete Ablehnung der Mathematik überwinden. Nur wenn die Mathematik zu einer populären Disziplin wird, hat die Schweiz eine Chance, ihren Digitalisierungsrückstand aufzuholen und vielleicht sogar ein Digitalisierungsleader zu werden.
Genniessen Sie diese Ausgabe zu Big, Open und Linked Data und denken Sie dabei daran: Ohne Mathematik ist das alles recht wenig bis nichts.
https://www.societybyte.swiss/wp-content/uploads/2016/09/Gruppe_09_def-opt.jpg12281920Reinhard Riedlhttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpReinhard Riedl2018-10-01 11:39:142019-01-14 12:11:19Oktoberausgabe: Digitalisierung ist eine ur-mathematische Disziplin
Ähnliche Beiträge
Es wurden leider keine ähnlichen Beiträge gefunden.
Wir leben in einer Gesellschaft, in der die Medienvielfalt unser kommunikatives Handeln nicht nur beeinflusst, sondern auch steuert. Das mit dem Buchdruck begann, wird in Zukunft vielleicht mit Robotern weitergeführt: Die Digitalisierung ist nicht mehr wegzudenken – auch nicht bei einer Profession, bei der der Mensch im Mittelpunkt steht.
Um die Sozialhilfegelder für den kommenden Monat zu bekommen, muss die Klientin online einen kurzen Fragebogen ausfüllen. Sie kann dies auf ihrem Smartpho- ne tun oder auf jedem anderem Gerät, das mit dem Internet verbunden werden kann. Ihr Sozialarbeiter, der die Zahlung prüft, heisst Avo. Avo ist braunhaarig, hat grüne Augen und eine ruhige Stimme, er ist einfühlsam und hilfsbereit. Er kann jede Frage beantworten, sei es eine rechtliche oder eine zu einem familiären Problem. Und er ist jederzeit verfügbar. Avo ist eine wichtige Ansprechperson für die Klientin geworden, er existiert – jedoch nur virtuell. Er ist eine intelligente Weiterentwicklung der heute üblichen Avatare.
Was heute noch etwas merkwürdig anmuten mag, könnte ein Zukunftsszenario der wirtschaftlichen Sozialhilfe sein. Wie Bancomaten die Schalterfrauen und -männer in den Banken ersetzt haben, könnten Avatare oder Roboter vielleicht bald die Sozialarbeitenden in der Beratung ersetzen. Eine Studie geht davon aus, dass 47 Prozent der aktuellen Arbeitsplätze in den USA in den nächsten ein bis zwei Jahrzehnten infolge der Digitalisierung ersetzt werden (vgl. Frey & Osborne, 2013, S. 38 ff.). Würde dieses Szenario auf die Schweiz zutreffen, hätten die Fachpersonen der Sozialen Arbeit nicht nur mit einer grösseren Anzahl Klientinnen und Klienten zu tun, sie würden eventuell gar selber zu dieser Klientel gehören. Noch sind wir zwar nicht soweit. Die Mediatisierung, also die «zeitliche, räumliche und soziale Durchdringung des Alltags mit Medien» (Nadia Kut- scher, Thomas Ley & Udo Seelmeyer, 2015, S. 3), und die Digitalisierung unseres Lebens bergen jedoch neue Herausforderungen für die Soziale Arbeit. Sie eröffnen aber auch Chancen.
Vom Buchdruck zur «Liquid Democracy»
Mit der Erfindung des Buchdruckes im 15. Jahrhundert wurde es möglich, Informationen schriftlich in Massenauflagen zu veröffentlichen. Dies bedeutete auch, dass die Informationsmacht im Laufe der Zeit immer weiter demokratisiert wurde – bis zum heutigen Inter-net, in dem jede und jeder publizieren kann. Wobei die «Liquid Democracy», die flüssige Demokratie, die eine Mischung aus direkter und repräsentativer Demokratie darstellt, wie sie das Internet ermöglicht, nicht unumstritten ist (vgl. Passig & Lobo, 2012). Doch ihre massive Wirkung ist klar ersichtlich, wie nicht zuletzt das Beispiel der «Panama Papers» zeigte: Eine Gruppe von Journalistinnen und Journalisten konnte durch weltweite Vernetzung ein Datenleck nutzen und eine Unmenge von Daten aufbereiten und über diverse Medien zeitgleich veröffentlichen; mit einschneidenden Folgen für die Anbietenden von Offshore-Dienstleistungen und deren Kundinnen und Kunden.
Veränderter Umgang mit Daten
Die unglaubliche Menge an Daten, auch «Big Data» genannt, die online abgelegt sind, werden unterschiedlich behandelt. Manche Daten über uns stellen wir selbst frei zugänglich ins Netz, wie zum Beispiel unsere Adresse und Telefonnummer auf den virtuellen «Gelben Seiten» oder über einen eigenen Blog. Andere Daten von uns landen im Netz, ohne dass wir es wissen, beispielsweise über Protokolle der Vereins-Mitarbeit, Social-Media-Plattformen oder durch Websites unserer Arbeitgebenden. Weitere Daten würden wir nie veröffentlichen und wir wünschen, dass sie sicher verwaltet werden, wie etwa die Inhalte unseres Online-Banking-Accounts.
Auch Klientinnen und Klienten der Sozialen Arbeit wünschen, dass die Daten, die wir über sie sammeln, vertrauenswürdig bearbeitet und abgelegt werden. Die genutzte Informatik-Infrastruktur sollte in einer sicheren Umgebung eingebettet sein, sie soll Angriffen von aussen standhalten. Weiter dürfen nur befugte Mitarbeitende Zugriff auf die Daten haben. Die Daten – sowohl in Papier- als auch in elektronischer Form – müssen vernichtet werden, wenn sie nicht mehr benötigt werden (vgl. dazu das Datenschutzgesetz des Kantons Bern).
Ein Zukunftsszenario könnte sein, dass die Klientinnen und Klientinnen sich ihre Daten zu Nutze machen: So wie heute einige Krankenkassen ihren Versicherten für einen Bonus anbieten, ihre Gesundheitsdaten freiwillig festzuhalten und wiederum den Kassen zur Verfügung zu stellen, könnten in Zukunft vielleicht die Klientinnen und Klienten einen direkten oder indirekten Nutzen aus den Daten generieren, die sie den Sozialarbeitenden zur Verfügung stellen.
Zwischen Kontaktaufnahme und Datenschutz
Besonders Fachpersonen der Sozialen Arbeit, die mit der jüngeren Klientel zu tun haben, stellen sich tagtäglich neue Herausforderungen: Jugendarbeiterinnen und Jugendarbeiter in der Soziokulturellen Animation müssen sich sowohl mit oft wechselnden Social-Media-Platt- formen (wie Facebook, SnapChat, Twitter, etc.) auskennen und ihr Publikum online auf dem gerade angesagten Medium abholen. Gleichzeitig müssen sie den Datenschutz berücksichtigen. Denn nicht jeder Kontakt, der online hergestellt werden kann, darf auf der jeweiligen Plattform weitergeführt werden. In der Arbeit mit Kindern und Jugendlichen stellen sich – im Unterschied zur den oft gut geregelten Informatik-Lösungen in der Sozialarbeit mit Erwachsenen – laufend Fragen zum Einsatz von neuen Medien. Mitarbeitende benötigen hohe Medienkompetenzen, die Leitung muss sich strategischen Fragen zum Einsatz von Social Media stellen.
Neue Beratungsformen senken die Hemmschwelle
Eine Vorreiterin in der Online-Beratung ist die Stiftung Pro Juventute, die auf eine über 100-jährige Geschichte zurückblicken kann. 1970 versendete Pro Juventute erstmals Elternbriefe, ab 1992 gab es das «Help- o-Fon», ab 1999 die Nummer 147 mit einer während 24 Stunden und 365 Tagen erreichbaren Telefonberatung für Kinder und Jugendliche. Heute ist eine ebenfalls rund um die Uhr erreichbare Multi-Channel-Helpline für Kinder, Jugendliche und deren Bezugspersonen in Betrieb.
Beraten wird noch immer über das Telefon, jedoch auch über E-Mail, das Internet, Chat und SMS. Dabei wird zwischen synchroner Beratung (Telefon, Chat) und asynchroner Beratung (Web, E-Mail und SMS) unterschieden. Die verschiedenen Beratungsformen ermöglichen den Ratsuchenden mit ihren Fragestellungen unterschiedliche Zugänge zu Beratung; wobei die eine Beratungsform die andere nicht konkurriert, sondern ergänzt.
Thomas Brunner, Leiter der Pro-Juventute-Beratungsangebote und Lehrbeauftragter an der BFH, sagt dazu: «Lange wurde Telefon- und Onlineberatung als Konkurrenz zur klassischen Face-to-Face-Beratung an- gesehen. Mittlerweile weiss man, dass diese neuen Beratungsformen die Schwelle erheblich senken, über persönliche Fragestellungen und Probleme ‹zu sprechen›. Menschen erhalten so die Möglichkeit, schwierige Themen ohne Gesichtsverlust und ohne Angst vor Stigmatisierung oder anderen negativen Konsequenzen zu bearbeiten.»
Studien bestätigen denn auch, dass Online-Beratung beispielsweise über Video-Chat genau so effektiv ist wie eine Präsenz-Beratung – zudem ist sie günstiger. Diese Erkenntnisse sollte sich die Soziale Arbeit zu Nutze machen, nicht nur hinsichtlich ökonomischer Gesichtspunkte, sondern auch um Menschen, die keine Präsenz-Beratung wünschen, trotzdem zu erreichen. Dass Medienkompetenz und die Weiterentwicklung der Sozialen Arbeit im Zuge der Digitalisierung nicht dem Zufall oder wie selbstverständlich den «Digital Natives» überlassen werden darf, diesem Umstand trägt die BFH Rechnung. Medienkompetenz und Wissen um die Potenziale der Digitalisierung dürfen nicht weiterhin unsystematisch und ausschliesslich aus dem Alltagswissen generiert werden, sondern bedürfen einer Professionalisierung – einerseits um den Klientinnen und Klienten gerecht zu werden und andererseits um den Anforderungen, welche die Digitalisierung und Mediatisierung an die Sozialarbeitenden stellt, vorausschauend begegnen zu können.
Glossar
Avatar
Ein Avatar ist eine Software bzw. ein ExpertInnen-System, das sich in Form einer animierten Person zeigt, teilweise sogar in 3D. Ein Avatar soll im besten Falle Menschen beraten und unterstützen; die heute eingesetzten Avatare sind jedoch noch nicht sehr selbständig. Sie werden in Human- und Agent-Avatar unterschieden. Ein Human-Avatar funktioniert interaktiv: Eine Person spricht durch den Avatar und kann deshalb auf Äusserungen und Aktionen eines Gegenübers reagieren. Human-Avatare haben den Nachteil, dass sie nicht zeit- und personenunabhängig genutzt werden können. Ein Agent-Avatar kann nicht interagieren, er macht nur das, wofür er programmiert ist: Er spricht bzw. reagiert nach Drehbuch. Ein Agent-Avatar ist orts-, zeit- und personenunabhängig einsetzbar.
Digitalisierung
Der Begriff Digitalisierung bezeichnet die Umwandlung analoger Signale in digitale Signale zum Zweck, diese elektronisch zu speichern oder zu verarbeiten. Im weiteren Sinn wird unter Digitalisierung der Wandel hin zu elektronisch gestützten Prozessen mittels Informations- und Kommunikationstechnik verstanden.
Digital Natives und Digital Immigrants
Mit Digital Natives sind die Personen gemeint, die mit der Digitalisierung aufgewachsen sind – als frühster Jahrgang gelten die 1980 geborenen. Die Digital Immigrants sind Personen, die sich erst im Erwachsenenalter mit der Digitalisierung auseinandersetzten.
Süddeutsche Zeitung. (2016). Panama Papers. Die Geheimnisse des schmutzigen Geldes [Website]. Abgerufen von http://panamapapers.sueddeutsche.de/
Verein sozialinfo.ch. (2013). Soziale Arbeit & Social Media. Leitfaden für Institutionen und Professionelle der Sozialen Arbeit. Bern: Edition Soziothek.
https://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webp00Fabienne Friedlihttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpFabienne Friedli2016-10-05 16:12:472016-10-24 15:12:33#SocialWork4.0 #Digital #BigData – Chancen und Herausforderungen der digitalen Gesellschaft
Ähnliche Beiträge
Es wurden leider keine ähnlichen Beiträge gefunden.
Big Data steht für verschiedenste Methoden, implizit in Daten vorhandene Informationen explizit zu machen. Das ermöglicht unter anderem mehr Personalisierung – von der Politik über den Produktverkauf bis zur Medizin!
In aller Regel wird der Begriff dafür verwendet, dass mit mathematischen Instrumenten Informationen, die in Datensätzen implizit vorhanden sind, explizit gemacht werden. Dafür werden typischerweise grosse und nicht selten unterschiedliche Datensätze zuerst zusammengeführt und dann mit Mathematikinstrumenten und Informatikwerkzeugen ausgewertet. Dabei gibt es drei Standardformen:
«Klassisches» Big Data schätzt den Wert einer Kenngrösse, indem es die Korrelation mit anderen Kenngrössen nutzt – Obama identifizierte so im Wahlkampf die noch unentschiedenen Wähler, auf die er dann seine Kampagne konzentrierte
Exploratives Big Data sucht nach bisher unbekannten Mustern, die eventuell Bedeutung haben – z.B. weil sie auf Risiken hinweisen oder interessante Gruppen von Kunden identifizieren
Big Data «auf dem Graphen» nutzt komplexe semantische Zusammenhänge – z.B. um das Fehlen von Informationen zu entdecken
Neueste Formen von Big Data gehen über diese drei Standardformen hinaus und experimentieren beispielsweise mit Simulationswerkzeugen. Vorstellbar ist auch die Kombination von statischen Werkzeugen mit weiteren Modellen der abstrakten Algebra.
Konkrete Beispiele
Was heisst das alles konkret? Nun, das Vorgehen beim klassischen Big Data ist eigentlich recht simpel. Es wird erst kompliziert, wenn man es abstrakt zu erklären versucht. Darum einige einfache Beispiele. Angenommen Sie besitzen Daten über das Kaufverhalten von als Person identifizierten Kunden. Und sie möchten ein neues Produkt lancieren und gezielt bewerben. Dann werden sie zuerst ähnliche, bereits existierende Produkte in ihrem Verkaufsportfolio identifizieren und dann jene Kunden herausfiltern, die diese Produkte öfters gekauft haben. Die Wahrscheinlichkeit ist hoch, dass sie sich für das neue Produkt ebenfalls interessieren werden und es macht Sinn, die Marketingkampagne für das neue Produkt auf sie zu konzentrieren. Im Customer Relationship Management vieler Banken wird seit Langem ein ähnliches Verfahren eingesetzt, um neue Finanzprodukte gezielt Kunden zu promoten.
Ein anderes konkretes Beispiel lieferte der letzte Präsidentschaftswahlkampfs in den USA. Im amerikanischen Präsidentschaftswahlkampf geht es darum, in genügend vielen Staaten die meisten Stimmen zu bekommen. In der Schlussphase des Wahlkampfs ist in vielen Staaten klar, wer die Mehrheit haben wird. Dort wird dann kaum mehr Wahlkampf betrieben, weil es eine Ressourcenverschleuderung wäre. Der Wahlkampf konzentriert sich ganz auf die umkämpften Staaten. Aber auch dort macht es wenig Sinn, Wähler anzusprechen, die sich bereits klar entschieden haben, wen sie wählen werden. Wenn es also dem Team eines Kandidaten gelingt, die Unentschiedenen zu identifiziert, kann es seine ganze Energie auf deren Überzeugung konzentrieren, während eventuell die Konkurrenz einen Grossteil ihrer Energie auf Wähler konzentriert, deren Entscheidung bereits feststeht. Da die verfügbaren Ressourcen beschränkt sind, bedeutet die Identifikation der Unentschiedenen einen grossen Vorteil. Und genau dieser Vorteil hatte wesentlichen Anteil daran, dass Obama auch die zweite Wahl gewann. Sein Team konnte mittels Big Data die Unentschiedenen identifizieren. Sie nutzten dabei die Tatsache, dass in den USA über Personen weit mehr Informationen einfach beschaffbar sind als in Europa – u.a. Informationen zum Kaufverhalten – und überprüft en und verbesserten die Ergebnisse von Big Data mit gezielten Experimenten.
Ein Beispiel für Big Data auf dem Paragraphen ist das Suchen nach Anhaltspunkte für organisierte Kriminalität, in dem man verdächtige
Beziehungskonstellationen oder Transaktionsketten identifiziert, die auf Geldwäscherei hinweisen.
Andere Beispiele sind intelligente Suchanwendungen in der Wissenschaft und im Patentwesen, die von einem scheinbaren Paradoxon profitieren: Es ist einfacher ein Dokument in einer Menge ähnlicher Dokumente zu finden (zwischen denen Querbeziehungen existieren) als in einer Menge sehr unterschiedlicher Dokumente (die zueinander keinen Bezug haben).
Ein typisches Beispiel für exploratives Big Data ist das Suchen nach guten Produktkombinationen. Seit Langem bietet der Verkauf von Extraausstattungen im Autohandel eine lukrative Einnahmequelle. Eine Zusammenstellung von Extras kann für Kunden dadurch besonders attraktiv gemacht werden, das sie als Paket verkauft wird, wobei der Kunde beim Kauf des ganzen Pakets einiges «spart» (verglichen mit der Summe der Einzelpreise für die Extras). Um verlockende Pakete zu schnüren, ist es aber notwendig, zu wissen, welche Kombinationen von Extras für Kunden besonders attraktiv sind. Deshalb wird in Daten über Kundenpräferenzen nach Mustern gesucht, die auf attraktive Paketzusammenstellungen hinweisen. Dieses Vorgehen wird freilich nicht nur im Autohandel praktiziert. Ganz ähnlich lassen sich so auch Produkte zusammensetzen, die am Ende teurer verkauft werden können als ihre Einzelbestandteile – nicht zuletzt im Lebensmittelhandel. Die Liste möglicher Beispiele ist lang. Wichtige Anwendungsbereiche für Big Data sind Marketing und Verkauf, Politikgestaltung (u.a. Stadtentwicklung, Sozial- und Gesundheitspolitik), öffentlichen Verwaltung (u.a. Verkehrsmanagement, in Zukunft eventuell Umgang mit Randalen), personalisierte Medizin und wissenschaftliche Forschung ganz generell. Das grosse Versprechen von Big Data ist dabei, dass schwierige und aufwendige Untersuchungen von kausalen Zusammenhängen («aus A folgt zwingend B») durch Korrelationsanalyse («A und B treten häufig gemeinsam auf») ersetzt werden können. Wobei insbesondere das klassische Big Data auf das Individuum spielt. Einzelne werden als Ziele für was auch immer ausgesucht, beziehungsweise bekommen sie personalisierte Angebote. Im Fall von personalisierten medizinischen Therapien ist der gesellschaftliche Nutzen hoch, mindestens kaum bestritten. Im Fall von personenbezogener manipulativer Werbung steht eine gesellschaftliche Bewertung von Big Data dagegen noch aus.
Das menschliche Big Data
Der Medienkünstler Peter Weibel thematisiert die Tatsache, dass wir alle in einer Big-Data-Welt leben. Tatsächlich können wir aus grossen Datenmengen relevante Information herauszufiltern und quasi eine Nadel im Heuhaufen finden – allerdings eine Nadel, an der ein Faden festgebunden ist, der uns das Finden erleichtert.
Das wichtigste Instrument für dieses menschliche Big Data ist die Nutzung von impliziten Hinweisen. Oft ist es die Summe von Details, von denen jedes für sich unbedeutend ist, die uns eine Lagebeurteilung ermöglicht – beispielsweise in der Polizeiarbeit. Wird ein ertappter Einbrecher zur Waffe greifen? Wird der Fanmarsch von Fussballfans in Gewalt ausarten? Die Antwort bestimmt den Fortgang des Geschehens. Sie lässt sich zwar nicht mit Sicherheit aus den verfügbaren Information ableiten, aber trotzdem kann sie von erfahrenen Polizisten ziemlich zuverlässig gegeben werden. Dabei kann man drei Phänomene beobachten: Erstens hängt die Zuverlässigkeit der Analyseergebnisse davon ab, dass die richtigen Informationen gesammelt werden. Zweitens wird der tatsächliche Ablauf durch Handlungen beeinflusst, die sich aus der Situationsanalyse ergeben. Teilweise haben wir es also mit selbsterfüllenden Prophezeiungen zu tun. Drittens lautet die Zielvorgabe deshalb nicht, möglichst präzise Prognosen zu generieren, sondern Geschäftsziele zu erreichen – in unserem Beispiel die Minimierung von Gewalt.
All das gilt auch für maschinelles Big Data:
Es ist entscheidend, dass man die passenden Informationen besitzt. Je nach verfügbaren Informationen kann ganz Unterschiedliches beim Anwenden der Big-Data-Werkzeuge herauskommen.
Big Data findet in einem dynamischen Prozess statt, in dem die Daten sich durch Handeln verändern können. Die Umsetzung beeinflusst die Richtigkeit der Prognose.
Big Data ist kein Glasperlenspiel mit dem Zweck von zweckfreien Zukunftsprognosen, sondern ein Mittel zur Nutzengenerierung im jeweiligen Geschäftskontext – sei es in der Wirtschaft, privat beim Wetten oder Pokern oder in der öffentlichen Verwaltung.
Denkfehler und verlockende Fiktionen
Eine Übertragung der Echtwelterfahrung auf Big Data ist also durchaus hilfreich. Sie beinhaltet aber auch die Gefahr, dass die Small-Data-Denkfehler aus dem Alltag uns auch bei der Nutzung von maschinellem Big Data in die Quere kommen. Wer den Satz von Bayes nicht verstanden hat, der sollte mit Big Data sehr vorsichtig umgehen. Zudem gibt es mehrere gefährliche Fiktionen, vor denen
man sich unbedingt hüten sollte.
Erstens sollte man sich immer bewusst sein, dass Modellannahmen das Ergebnis von Big Data entscheidend beeinflussen, auch dann, wenn wir scheinbar ganz ohne Modelle Daten analysieren. Denn schon bei der Erzeugung von Daten spielen Modelle eine entscheidende Rolle. Es gibt in dieser Hinsicht keine natürlichen Rohdaten (Rohdatenfiktion).
Zweitens können auch grossen Datenmengen einen klaren Bias haben. Nur weil wir viele Daten sammeln, können wir daraus nicht ableiten, dass unsere Daten in irgendeiner Weise repräsentativ sind (Statistikfiktion).
Drittens liefert Big Data nicht einfach so gute Resultate (Simplizitätsfiktion) – es verlangt mindestens mathematische, technische, fachliche und rechtliche Kompetenzen.
Viertens können Ergebnisse von Big Data Analysen ohne verständliche Erklärungsmodelle für die zugrunde liegenden Zusammenhänge oft nicht sinnvoll eingesetzt werden (Korrelationsfiktion). Stellen Sie sich einen Polizeieinsatz von Wasserwerfern vor, der damit begründet wird, dass Big Data Massenunruhen prognostiziert hat – und im Nachhinein stellt sich heraus, dass eine überdurchschnittlich hohe Zahl roter Halstücher der Auslöser war.
Fünftens schaffen viele Daten noch keine Transparenz (Transparenzfiktion).
Sechstens ist dauerhafte Anonymisierung schwer zu garantieren (Anonymisierungsfiktion).
Siebtens bringen Big Data nicht notwendigerweise Nutzen für alle (Fairnessfiktion). Wer über die Daten von anderen verfügt, kann damit viel Gewinn machen. Die Masse der Datenlieferanten bekommt zwar meist im Tausch kostenlose Online-Dienste, hat aber keinen Anteil an den Milliardengewinnen und gerät im schlimmsten Fall sogar in ein Abhängigkeitsverhältnis.
Last but not least: Was die Anwendungen von Big Data in der Politik betrifft, so besitzt die Vorstellung einer Welt mit einer computergestützten Demokratie, in der Fakten eine viel grössere Rolle spielen als in unserer heutigen Demokratie, recht viel Alptraumpotenzial – gerade weil dabei komplexe Probleme mit Computern vereinfacht werden. Denn es ist zu Recht sehr umstritten, dass man hohe Komplexität durch Automatisierung kontrollieren kann (Automatisierungsfiktion). Darüber hinaus kann der Einsatz von Big Data für Zukunftsprognosen in der Politik zu einer «Geschichtsbremse» führen. Da Big Data die Zukunft nur aus der Vergangenheit ableiten kann, wird durch eine unreflektierte «gläubige» Anwendung der Raum für kreative Innovationen eingeschränkt. Das ist gerade dort, wo die nächste (prognostizierbare) Wahl wichtiger ist als der langfristige (viel weniger prognostizierbare) Erfolg, eine echte Gefahr.
Schlussfolgerung
Big Data besitzt ein gewaltiges, derzeit nur in Ansätzen abschätzbares, Nutzenpotential. Es wird die Wirtschaft, unser persönliches Leben und das Staatswesen sehr stark verändern. Ignoriert die öffentliche Verwaltung das Thema, wird sie in Zukunft ihre Aufgaben nicht mehr zufriedenstellend erfüllen können. Gleichzeitig schafft aber Big Data auch neue, grosse Gefahren für die Gesellschaft, die sich verheerend auswirken könn(t)en. Es ist deshalb Zeit, dass wir uns ernsthaft mit Big Data auseinandersetzen!
In der Schweiz verursacht der Transportsektor rund ein Drittel des gesamten Energieverbrauchs. Das Forschungskompetenzzentrum SCCER Mobility entwickelt Wissen und Technologien, die wesentlich sind für den Übergang von den aktuell auf fossilen Brennstoffen basierenden Transportsystemen zu ökologischeren Lösungen.
Das SCCER Mobility (siehe Begriffserklärung am Ende des Beitrags) will die komplexe Dynamik der Mobilität, des Transports und der gesamten Energiesysteme – einschliesslich ihrer Wechselwirkungen mit der Stadtplanung – verstehen lernen. Der Kompetenzbereich «Dencity – Urbane Entwicklung und Mobilität» der Berner Fachhochschule BFH hat zusammen mit dem Institut für Umwelt der ETH Zürich, das Ziel, die Konsequenzen der Wechselwirkung zwischen den bestehenden Gebäudetypologien und den CO2-Emissionen aus den privaten Haushalten aufzuzeigen.
Um dieses Ziel zu erreichen, wurde das automatisierte Dencity-Analysemodell (ADAM) entwickelt, das bestehende Gebäudetypologien (siehe Grafik) für die ganze Schweiz identifiziert. Dieses Modell kann mit einer immensen Menge an unterschiedlichem Dateninput umgehen. Zu diesem Zweck muss ADAM vollständig integrierbar sein in das Ökosystem des bestehenden schweizerischen Geografischen Informationssystems GIS (Informationssystem zur Erfassung, Bearbeitung, Organisation, Analyse und Präsentation räumlicher Daten). ADAM ist in der Lage, die spezifischen Koordinatensysteme der verschiedenen Dateninputs zu identifizieren, abzustimmen und zu überlagern. Das automatisierte Analysemodell basiert auf einem eigenen Algorithmus, wobei dieser die Verknüpfung von Open-Source-Daten, Daten aus dem schweizerischen Bundesamt für Statistik, dem Bundesamt für Raumentwicklung sowie Daten zu CO2-Emissionen je Einwohner kombiniert. Der spezifische Output von ADAM ist eine neuartige Datenbank sowie Karte für alle bestehenden Gebäudetypologien der Schweiz mit ihrer Haushaltsidentifizierung, Koordinaten und CO2-Ausstoss. Diese Datenbank unterstützt nun bei stadt- und raumplanerischen Analysen und Optimierungen und dient Städten und Gemeinden als Entscheidungsgrundlage für Planungen.
Die durch ADAM analysierten Gebäudetypologien von links nach rechts mit der entsprechenden Farbcodierung: Punkthäuser, geschlossener Block, Zeilenhäuser, offener Block; Spezialfälle und Sonderformen werden in eine separate Kategorie aufgenommen.
Weiterführendes Forschungspotenzial
Die Analysemöglichkeiten, die sich in Bezug auf Planungsszenarien erschliessen, sind immens. ADAM kann als Zugang zu «Big Data» (Datenmengen, die zu immens und komplex sind, als dass sie mit manuellen und klassischen Methoden der Datenverarbeitung auszuwerten wären) und zur räumlichen Analyse gesehen werden. Es bereitet «Big Data» und Komplexität für das Tagesgeschäft von Architekten, Planern und Ingenieuren auf. Die Stärken des Analysemodells sind die Handhabung grosser, komplexer Datenmengen sowie die Extraktion der notwendigen Grundlagen. ADAM identifiziert Daten, verarbeitet, kombiniert und ordnet zu, um eine definierte Frage zu lösen.
SCCER Mobility
Im Rahmen des Aktionsplans «Koordinierte Energieforschung Schweiz» hat die KTI den Auftrag, den Aufbau interuniversitär vernetzter Forschungskompetenzzentren, sog. Swiss Competence Centers for Energy Research (SCCER), zu finanzieren und zu steuern. Das SCCER Efficient Technologies and Systems for Mobility (SCCER Mobility) ist im Aktionsfeld «Effiziente Konzepte, Prozesse und Komponenten in der Mobilität» angesiedelt.
Ernst Hafen sieht unsere digitale Identität in den Händen von Google, Facebook und Co. Ein Weg, diese Artvon Leibeigenschaft aufzulösen und die Kontrolle über all seine persönlichen Daten, vor allem die Gesundheitsdaten,zu erhalten, wäre eine genossenschaftlich organisierte Datenbank.
Interview: Reinhard Riedl
Was ist Ihre Vision im Verein Daten und Gesundheit?
Wir haben als Individuen zunehmend auch eine digitale Persönlichkeit. Damit begeben wir uns in eine Art Leibeigenschaft. Wir akzeptieren mit der Nutzung beispielsweise von Google, Facebook und Twitter, dass diese Dienste Daten über uns sammeln. Das primäre Ziel des Vereins ist, die Kontrolle über alle Gesundheitsdaten zu erhalten. Es ist meine Überzeugung, dass die Leute freiwillig mitmachen und einen Beitrag dazu leisten. Habe ich zum Beispiel eine seltene Krankheit, bin ich daran interessiert, möglichst rasch eine Therapie zu finden. Dafür möchte ich mich nicht innerhalb eines Gesundheitssystems, sondern global vernetzen können. Die Individuen könnten dadurch selbstständig Treiberinnen und Treiber einer personalisierten Gesundheit werden beziehungsweise
dieser persönlichen Datenökonomie, die entsteht.
Können Sie das Ziel einer personalisierten Gesundheit beziehungsweise einer personalisierten Medizin näher umschreiben?
Personalisierte Medizin heisst, dass wir alle unterschiedlich sind. Heute kennt man zunehmend die molekularen Grundlagen, die für diese unterschiedlichen Empfindlichkeiten verantwortlich sind. Sie können das mit einem Buch vergleichen: Wäre jeder tausendste Buchstabe ein Druckfehler, würde das den Sinn des Buchs nicht verändern. Aber im Erbgut sind diese kleinen Unterschiede verantwortlich für unser Aussehen und für die Empfindlichkeit für Krankheiten oder für die Reaktionen auf Medikamente. Wir sind am Anfang einer Revolution in der personalisierten Medizin. Wenn wir weiterkommen wollen, müssen wir alle Daten erheben, die wir heute können. Einerseits durch Genomanalysen, auf der anderen Seite aber auch über Mobile Health Apps, die alle möglichen Gesundheitsparameter über das ganze Leben aufzeichnen. Um wirklich genaue Voraussagen machen zu können, sind die Daten von Millionen von Leuten nötig. Es ist ein Big-Data-Problem, dass man nicht anhand einzelner Gensequenzen analysieren kann, sondern nach Mustern suchen muss, die aus diesen Datensätzen herauskommen.
Es gibt die These, dass die sozialen Lebensumstände einen Einfluss auf unsere Krankheitsrisiken haben. Bräuchte man nicht zusätzlich die Daten über das Leben, die digitale Identität?
Da haben Sie recht. Wie viel ich mich bewege, wie viel ich Auto fahre, wo ich lebe, welche Reisen ich mache, all das sind natürlich Sachen, die unsere Gesundheit beeinflussen. Da sind die Daten zentral, die wir zusehends über Mobile-Health-Technologien aufnehmen können. Ich weise auch immer gerne darauf hin, dass Google wahrscheinlich mehr über Ihren Gesundheitszustand weiss als Ihre Ärztin oder Ihr Arzt: welche Websites Sie anschauen, welche Tweets Sie machen, auch welche Telefongespräche Sie führen. Damit hat Google viel aggregiertere Information als Ihr Arzt, der bei Ihrer letzten Untersuchung Ihren Gesundheitszustand mit ein paar Notizen festgehalten hat. Deshalb sind all die Informationen, die Google hat, sehr relevant für die Gesundheit.
Ernst Hafen ist Professor am Institut für Molekulare Systembiologie und ehemaliger Präsident der ETH Zürich. Nebst seinen 26 Jahren in der akademischen Forschung, für die er mit mehreren Preisen ausgezeichnet wurde, setzte er sich aktiv für den Dialog zwischen Forschung und Gesellschaft und für die Umsetzung wissenschaftlicher Erkenntnis in kommerzielle Produkte ein. Als gelernter Genetiker hat Ernst Hafen ein starkes Interesse an der Humangenetik und an der personalisierten Medizin. Er postuliert, dass eine individuelle Kontrolle über persönliche Gesundheitsdaten einen Schlüsselfaktor für eine bessere und effektive Gesundheitsversorgung darstellt. Im Jahr 2012 gründete er den Verein Daten und Gesundheit. Dieser beabsichtigt, die Errichtung einer genossenschaftlich organisierten Gesundheitsdatenbank in der Schweiz zu fördern.
Heisst das, dass Google, Facebook und Co. mit der innovativen Nutzung unserer Daten Geld verdienen und für die anderen nichts bleibt?
Nein, ich glaube, das geht auch anders, wir haben nur noch nicht gelernt, damit umzugehen. Wir sind in eine Leibeigenschaft reingeschlittert, weil wir die Services gern nutzen, das Internet faszinierend finden und es gratis ist. Aber ich bin überzeugt, dass das nicht so weitergehen kann. Eine genossenschaftlich organisierte Datenbank, wo jeder freiwillig ein Konto eröffnen kann und dort all seine Daten sammeln und vor allem entscheiden kann, was er damit macht, ist im Prinzip die Antwort auf diese digitale Leibeigenschaft. Google kann weiterhin meine Klicks und meine Querys haben, aber ich möchte Kopien all dieser Events erhalten.
Was sind im Augenblick die grossen Herausforderungen, wenn man eine solche Genossenschaftsidee für die Schweiz realisieren will?
Die Herausforderung ist einerseits, eine Datenbank zu bauen, die so sicher ist, dass die Leute ihr vertrauen. Andererseits muss man den Leuten sagen: «Hört mal, ihr seid in dieser Leibeigenschaft. Ihr hättet eigentlich viel mehr davon, wenn ihr alle Daten auf einem Konto hättet.» Wenn wir über persönliche Daten und insbesondere Gesundheitsdaten reden, geht es oft darum, dass der Staat entscheidet, was damit gemacht wird. Aber die Wirtschaft zum Beispiel wird stimuliert, weil man mit seinem Geld machen kann, was man will. Dieses Umdenken ist bei persönlichen Daten noch nicht passiert.
Es ist schwer vorstellbar, wie so grosse Datenmengen, die viele Lebensbereiche betreffen, anonym in einer Datenbank angelegt werden können. Wie kann man mit diesem Problem erfolgreich umgehen?
Wichtig ist, dass die Daten auf den Konten nie herausgegeben werden. Es können lediglich Anfragen oder Querys für Daten gemacht werden, die Sie freigeben. Ein weiteres Ziel der Genossenschaft ist, den Bürgerinnen und Bürgern und nicht den Shareholdern zu dienen. Die Genossenschaft schaut, dass keine identifizierbaren Daten rausgegeben werden. Das Identifizieren von Daten kommt erst, wenn man mehrere Silos von Daten hat. Wenn man diese zusammenführen würde, könnte man nach und nach die betreffenden Personen identifizieren. Das kann man nie ganz vermeiden, aber man kann es minimieren.
Wie kann man Daten aus ganz unterschiedlichen Quellen zusammenführen?
Wir sind darauf angewiesen, dass wir mit den Datenprovidern zusammenarbeiten und Apps entwickeln können, die den Import dieser Daten automatisch generieren. Es bleibt eine Tatsache, dass wir eine Riesenmenge von Daten in verschiedenen Qualitäten und mit verschiedenen Standards haben. Alle Initiativen, die auf eine Top-down-Standardisierung ausgerichtet waren, sind weitgehend gescheitert. Aber erstens sind heute die Suchtechnologien so gut, dass man aus vielen strukturierten und unstrukturierten Daten viel Information bekommt. Zweitens glauben wir, dass die Leute selber einen grossen Beitrag zur Kreation ihrer eigenen Daten leisten und uns mitteilen, wenn Daten fehlerhaft sind. Das wird die Qualität erhöhen. Letztlich wird diese Genossenschaft auch über Big-Data- Analytics und Machine Learning damit beginnen können, die Daten bottom up zu standardisieren.
Was ist der Unterschied Ihrer Bestrebungen zu denjenigen von E-Health Schweiz, wie es vom Bundesamt für Gesundheit organisiert wird?
Die beiden Initiativen vom Verein Daten und Gesundheit und vom Bundesamt für Gesundheit (BAG) sind komplementär zueinander. E-Health Schweiz, wie es vom BAG organisiert wird, hat das absolut gerechtfertigte Bedürfnis, die Schnittstellenproblematik zu verbessern, sodass die Daten im schweizerischen Gesundheitssystem besser fliessen. Unsere Motivation ist das primäre Empowerment der Bürgerinnen und Bürger. E-Health Schweiz geht es um die Patientendaten, uns geht es um alle persönlichen Daten. Weiter sind wir global und nicht national aufgestellt. Es kann sein, dass es in 20 Jahren keine E-Health-Schweiz-Strategie gibt, aber dass die meisten Bürgerinnen und Bürger bereits ein Konto haben und ihrer Ärztin oder ihrem Arzt Zugang zu diesem Konto geben können.
Wo wird das Gesundheitswesen in 30 Jahren sein?
Eine pessimistische Antwort wäre, dass sich nicht viel ändern wird, weil das ganze Gesundheitssystem sehr träge ist. Ich glaube aber nicht daran. Vor 20 Jahren hat auch noch niemand die Smartphones vorausgesagt. Um die Schnittstellenproblematik zu lösen, müssen alle im schweizerischen Gesundheitssystem mitmachen, sonst funktioniert es nicht. Aber das Finden von effektiveren Medikamenten oder das frühzeitige Entdecken von Nebenwirkungen von Medikamenten sind globale Fragen, die nicht immer durch lokale Gesundheitssysteme gelöst werden können. Ich glaube, dass wir hier in den kommenden 30 Jahren eine Bürgerzentrierung hinbekommen. Einfach weil es heute durch digitale Daten möglich ist. Jetzt müssen wir nur noch die Awareness schaffen.
Unsere traditionelle Abschlussfrage: Wie soll der Staat der Zukunft aussehen?
Es täte der Schweiz gut, die Demokratie und den Kapitalismus zu hinterfragen. Es braucht gesetzliche Rahmenbedingungen, aber es braucht auch eine grössere Selbstbestimmung des Individuums. Wenn wir von Datenschutz sprechen, sprechen wir immer davon, dass der Staat Regeln aufstellen muss, um Daten zu schützen. Das ist ein passives Modell. Ein demokratisch aktives Modell ist die digitale Selbstbestimmung. Es sollte nicht eine staatliche Genossenschaft geben, es sollte mehrere geben, wie es mehrere Banken gibt. Solange die Daten miteinander verlinkt sind, wie sie das im Finanzbereich über SWIFT auch sind, haben wir im Prinzip die Datenökonomie geschaffen. Das gibt der Bezeichnung Demokratie nicht nur ein politisches Gewicht, sondern auch eine ökonomische selbstbestimmte Kraft, die globale Auswirkungen hat. Es täte der Schweiz gut, hier eine Vorreiterrolle zu spielen.
https://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webp00Reinhard Riedlhttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpReinhard Riedl2016-10-02 11:32:222016-10-24 15:10:01«Wir sind in eine Leibeigenschaft reingeschlittert»
Ähnliche Beiträge
Es wurden leider keine ähnlichen Beiträge gefunden.
Damit die Behördendaten ihr Nutzenpotenzial für Wirtschaft und Gesellschaft entfalten können, müssen sie umfassend und systematisch zur Verfügung gestellt werden. Von besonderem Interesse sind Basisregister sowie Geodaten zur Lokalisierung dieser Entitäten. Zusammen mit weiteren Behördendaten zu Themen wie Verkehr, Energie oder Gesundheitswesen bilden diese eine immaterielle Infrastruktur, deren Kohärenz, Qualität und Verfügbarkeit über den erfolgreichen Aufbau einer Datenwirtschaft entscheidet. So wie öffentliche Schienen- und Strasseninfrastrukturen die Entwicklung der Industriegesellschaft ermöglicht haben, benötigt die Wissensgesellschaft eine nationale Dateninfrastruktur – Open Data ist der erste Schritt auf diesem Weg.
Daten sind kein «Erdöl»
Obwohl Daten immer wieder als das «Erdöl» des 21. Jahrhunderts bezeichnet werden, ist diese Metapher falsch. Im Gegensatz zu Erdöl können Daten als Infrastrukturressource – vergleichbar einem Leuchtturm – ohne Rivalität genutzt werden. Die beliebige Kopierbarkeit digitaler Daten erlaubt es, diese zu nutzen, ohne jemand anderen an der Mitnutzung zu hindern. Zudem sind Daten ein Investitionsgut, das zur Erstellung von Dienstleistungen und Endprodukten eingesetzt werden kann und für beliebig viele unterschiedliche Zwecke verwendbar ist (OECD 2014: 24).
Die OECD kommt in ihrem Bericht «Data- driven Innovation for Growth and Well- being» zum Schluss, dass Daten eine wichtige Ressource darstellen, die zu neuem Wissen, neuen Produkten, Prozessen und Märkten führen können, und bezeichnet diesen Trend als datenbasierte Innovation (ebd. S. 4). Daten können einerseits als Infrastrukturressource dienen, die grundsätzlich von einer unbeschränkten Anzahl Nutzern für eine unbegrenzte Anzahl Zwecke für Dienstleistungen und Endprodukte eingesetzt werden kann, und andererseits als Input für die Analyse, welche neue Erkenntnisse und automatisierte Entscheidungen erlaubt.
Wertschöpfung mit Daten
Die datenbasierte Innovation ist kein linearer Prozess; Feedback-Loops sowie wiederkehrende Phasen der Wertschöpfung sind Teil des Prozesses (vgl. Abbildung 1). Die Wertschöpfungskette der Daten vom ersten Erfassen bis zur Aussage in der Statistik ist heute allerdings immer noch eine lange Folge von Medienbrüchen. Unterschiedlichste Anforderungen und Systeme erschweren den Be- schaffungs- oder Verarbeitungsprozess für Daten, Informationen und Inhalte. Das verlangsamt den Prozess nicht nur, sondern mindert auch die Qualität der Daten und erschwert deren Interpretation unnötigerweise.
Abb. 1: Der Data Value Cycle (OECD 2014: 23)
Der positive Einfluss datenbasierter Innovation ist nicht auf den ICT-Wirtschaftszweig limitiert. Die Tätigkeiten von Finanzdienstleistern sowie Firmen in den Bereichen Business und Professional Services sind äussert datenintensiv, diese Unternehmen werden daher in Zukunft noch vermehrt in die Entwicklung datenbasierter Innovationen investieren. Daneben sieht die OECD im Gesundheits- und im Ausbildungssektor sowie in der öffentlichen Verwaltung Chancen für datenbasierte Innovationen, die in verhältnismässig kurzer Zeit grosse Auswirkungen haben können (ebd. S. 5).
Data Governance
Um datenbasierte Innovation zu fördern, braucht es eine strategische Steuerung und Koordination der Datenproduktion, Datenpublikation und Datennutzung des Bundes über die organisatorischen Grenzen der Verwaltung hinweg («Data Governance»). Damit Daten als Infrastrukturressource genutzt werden können, benötigt es insbesondere geeignete Rahmenbedingungen für den Zugang («access») zu den Daten sowie das Teilen («sharing») und die Interoperabilität («interoperability») der Daten. Für die Regelung des Datenzugangs eröffnet sich ein Spektrum von geschlossenen Daten, die nur dem Data Owner zugänglich sind, bis zu offenen Daten, zu welchen die Öffentlichkeit ohne Einschränkungen Zugang hat. Auch für die Weiternutzung der Daten eröffnen sich verschiedene Optionen, von der Unterbindung jeglicher Weiternutzung bis zur freien Weiterverwendung ohne jede Einschränkung («public domain»). Das wichtigste Hindernis für den freien Fluss der Daten zwischen potenziellen Nutzern sind Datensilos. Gerade auch innerhalb grosser Firmen und in der öffentlichen Verwaltung behindern diese den freien Fluss der Daten über organisatorische Grenzen hinweg. Daher muss die Data Governance insbesondere auch die Vernetzung und Integration der Datenbestände innerhalb einer Organisation regeln. Linked Data ist ein wichtiger technischer Ansatz, um diese Anfor- derung an die Vernetzung und Integration von Datenbeständen über organisatorische Grenzen hinweg zu erfüllen. Das Programm «Good Basic Data for Everyone» in Dänemark ist ein gutes Beispiel für den erfolgreichen Aufbau einer nationalen Dateninfrastruktur. Die Grundannahme besteht darin, dass die Öffnung qualitativ hochstehender Daten als Infrastruktur Behörden ermöglicht, ihr Kerngeschäft organisationsübergreifend besser erfüllen zu können. Zusätzlich gilt in Dänemark die Datenliberalisierung als Innovationstreiber. In Grossbritannien ist seit 2013 ein ähnliches Programm unter dem Namen «National Information Infrastructure» in Gang.
Ausgangspunkt Open Data
Seit wenigen Jahren haben in der Schweiz einzelne Bundesämter, Kantone und Städte damit begonnen, Behördendaten punktuell der Öffentlichkeit als Open Data zur freien Nutzung zur Verfügung zu stellen. Das ist erfreulich und de facto ein erster Schritt auf dem Weg zu einer nationalen Dateninfrastruktur. Aber es ist bei Weitem nicht ausreichend. Damit die Behördendaten ihr enormes Nutzenpotenzial für Wirtschaft, Gesellschaft und Kultur effektiv entfalten können, müssen sie umfassend und systematisch zur Verfügung gestellt werden. Von besonderem Interesse sind dabei diejenigen Basisdaten, welche in allen Lebensbereichen der Wissensgesellschaft permanent zur Anwendung kommen: Register zu Personen, Firmen und Gebäuden, Adressen sowie Geodaten zur Lokalisierung dieser Entitäten.
«Typically, Key Registers hold essential and frequently used public sector information pertaining to persons, companies, land, buildings and other ‹infrastructural› elements critical to the proper functioning of government. The rationale for establishing a System of Key Registers is the notion that it is in fact infrastructure that is indispensable for fulfilling governmental policy ambitions and societal needs in the context of the evolving (digital) relationship between a government and its citizens and companies.» (de Vries/ Pijpker 2013: 4).
Zusammen mit weiteren Daten des öffentlichen Sektors, z.B. von Verkehr, Energie, Gesundheitswesen, öffentlichen Finanzen oder Wetter, bilden diese Basisdaten eine immaterielle Infrastruktur, deren Kohärenz, Qualität und Verfügbarkeit über den erfolgreichen Aufbau einer Datenwirtschaft und -kultur entscheidet.
Vision Nationale Dateninfrastruktur Schweiz
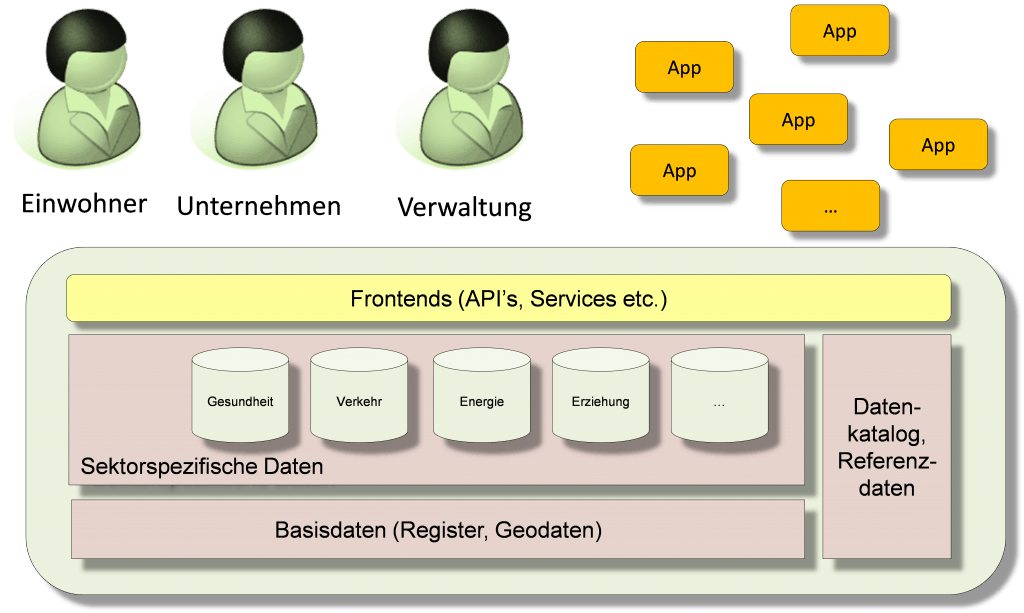
Die EU-Kommission sieht die Realisierung eines digitalen Binnenmarktes als eine politische Priorität. Die Infrastruktur – inklusive Dateninfrastruktur – ist auch aus ihrer Perspektive eine zentrale Voraussetzung, um das Potenzial der digitalen Wirtschaft auszuschöpfen. Will die Schweiz in den kommenden Jahren das Potenzial datenbasierter Innovationen für wirtschaftliches Wachstum und soziales Wohlergehen nutzen, dann ist die Erschliessung und Vernetzung der bis anhin in einzelnen Silos isolierten Datenbestände der öffentlichen Verwaltung und des gesamten öffentlichen Sektors eine zwingende Voraussetzung. Die nationale Dateninfrastruktur muss beginnend bei den Basisregistern für Unternehmen, Gebäude und Personen sowie bei den Geobasisdaten alle Datensätze aus Bereichen wie Gesundheit, Energie, Verkehr, Erziehung etc. umfassen, welche für das Funktionieren der Schweiz relevant sind. Diese Datenbestände sind nicht länger als isolierte Installationen zu betrachten, sondern als Teile einer übergeordneten immateriellen Infrastruktur, welche die Entwicklung datenbasierter Dienstleistungen und die Gewinnung relevanter Erkenntnisse zur Schweiz ermöglicht. Diese Infrastruktur muss den Zugang zu den Daten über Onlinedatenkataloge, Download-Services, API etc. so offen und einfach wie möglich gestalten und nur dort einschränken, wo es rechtliche Auflagen wie der Schutz der Privatsphäre zwingend verlangen. Nebst den Basisdaten sowie Daten aus verschiedenen Wirtschafts-, Verwaltungs- und Wissenschaftsbereichen sind Verzeichnisse der Datenbestände, Referenzdaten, Terminologien und weitere Hilfsmittel zur Erschliessung der Daten Bestandteil der Dateninfrastruktur.
Abb. 2: Nationale Dateninfrastruktur
Die nationale Dateninfrastruktur soll die Erstellung von datenbasierten Dienstleistungen und Applikationen über unterschiedliche Anwendungsbereiche hinweg mit minimalem Aufwand ermöglichen. Sie ist Plattform und Motor für organisationsübergreifende Zusammenarbeit und datenbasierte Innovationen.
Quellen
de Vries, Marc/Pijpker, Udo (2013): The Danish Dash. A short story unravelling the Danish magic of shaping a System of Key Registers in less than nine months. The Hague.
European Commission (2015): A Digital Single Market Strategy for Europe, May 2015, http://ec.europa.eu/priorities/digital-single-market_en
OECD (2014): Data-driven Innovation for Growth and Well-being, Interim Synthesis Report, October 2014, http://www.oecd.org/sti/inno/data-driven-innovation-interim-synthesis.pdf.
https://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webp00Alessia Neuronihttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpAlessia Neuroni2016-10-02 08:37:112025-12-02 09:54:53Open Data als erster Schritt zum Aufbau einer nationalen Dateninfrastruktur
Ähnliche Beiträge
Es wurden leider keine ähnlichen Beiträge gefunden.
Wir können Cookies anfordern, die auf Ihrem Gerät eingestellt werden. Wir verwenden Cookies, um uns mitzuteilen, wenn Sie unsere Websites besuchen, wie Sie mit uns interagieren, Ihre Nutzererfahrung verbessern und Ihre Beziehung zu unserer Website anpassen.
Klicken Sie auf die verschiedenen Kategorienüberschriften, um mehr zu erfahren. Sie können auch einige Ihrer Einstellungen ändern. Beachten Sie, dass das Blockieren einiger Arten von Cookies Auswirkungen auf Ihre Erfahrung auf unseren Websites und auf die Dienste haben kann, die wir anbieten können.
Wichtige Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Google Analytics Cookies
These cookies collect information that is used either in aggregate form to help us understand how our website is being used or how effective our marketing campaigns are, or to help us customize our website and application for you in order to enhance your experience.
If you do not want that we track your visit to our site you can disable tracking in your browser here:
Andere externe Dienste
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.
Google Webfont Settings:
Google Map Settings:
Google reCaptcha Settings:
Vimeo and Youtube video embeds:
Other cookies
The following cookies are also needed - You can choose if you want to allow them:

 Create PDF
Create PDF
 Ernst Hafen ist Professor am Institut für Molekulare Systembiologie und ehemaliger Präsident der ETH Zürich. Nebst seinen 26 Jahren in der akademischen Forschung, für die er mit mehreren Preisen ausgezeichnet wurde, setzte er sich aktiv für den Dialog zwischen Forschung und Gesellschaft und für die Umsetzung wissenschaftlicher Erkenntnis in kommerzielle Produkte ein. Als gelernter Genetiker hat Ernst Hafen ein starkes Interesse an der Humangenetik und an der personalisierten Medizin. Er postuliert, dass eine individuelle Kontrolle über persönliche Gesundheitsdaten einen Schlüsselfaktor für eine bessere und effektive Gesundheitsversorgung darstellt. Im Jahr 2012 gründete er den Verein Daten und Gesundheit. Dieser beabsichtigt, die Errichtung einer genossenschaftlich organisierten Gesundheitsdatenbank in der Schweiz zu fördern.
Ernst Hafen ist Professor am Institut für Molekulare Systembiologie und ehemaliger Präsident der ETH Zürich. Nebst seinen 26 Jahren in der akademischen Forschung, für die er mit mehreren Preisen ausgezeichnet wurde, setzte er sich aktiv für den Dialog zwischen Forschung und Gesellschaft und für die Umsetzung wissenschaftlicher Erkenntnis in kommerzielle Produkte ein. Als gelernter Genetiker hat Ernst Hafen ein starkes Interesse an der Humangenetik und an der personalisierten Medizin. Er postuliert, dass eine individuelle Kontrolle über persönliche Gesundheitsdaten einen Schlüsselfaktor für eine bessere und effektive Gesundheitsversorgung darstellt. Im Jahr 2012 gründete er den Verein Daten und Gesundheit. Dieser beabsichtigt, die Errichtung einer genossenschaftlich organisierten Gesundheitsdatenbank in der Schweiz zu fördern.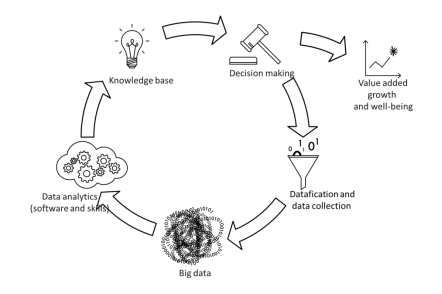
 Beiträge als RSS
Beiträge als RSS