
Welchen Beitrag könnten die Digital Humanities zu einer anwendungsorientierten Geschichtsschreibung (applied history) beitragen? Der folgende Beitrag will aufzeigen, wie serielle Quellen analysiert werden können, um für die Geschichtsschreibung präzise Aussagen über das Aufkommen von Begriffen in der Politischen Kommunikation zu treffen.
Das Handwerk der HistorikerInnen ist die Datenanalyse schlechthin. Wobei es sich mit Ausnahme der in der Wirtschaftsgeschichte seit den 1970er Jahren verwendeten Kliometrie (die Anwendung ökonomischer oder ökonometrischer Modelle) eben nicht um Daten handelt, welche man quantitativ auswerten könnte, sondern in der Regel um überlieferte Texte. Daran ändert sich auf den ersten Blick auch nicht viel, wenn diese Texte maschinenlesbar (also digital) vorliegen. Wenn es sich also um Texte handelt, dann werden in der Geschichtsschreibung mit der historisch-kritischen Methode Fragen an eine überlieferte Quelle gestellt. Warum adressiert jemand zu einer bestimmten Zeit in welcher Absicht eine bestimmte Botschaft? Dies geschieht, indem in der Regel Texte interpretiert werden, wobei der Kontext ebenso wichtig ist, innerhalb dessen ein Dokument entstanden ist. Die historisch-kritische Methode hat letztlich zum Ziel, zu «verstehen, warum etwas ist», bzw. auf das Anwendungsgebiet der Geschichte bezogen, «warum etwas so geschehen ist».
Der Aufstieg Hitlers zum Diktator innerhalb einer parlamentarischen Demokratie kann alleine mit einem quantitativen Verfahren der Datenanalyse nie erklärt werden. Welche Hypothesen Historiker formulieren, hängt letztlich aber auch von ziemlich viel Intuition ab und davon, dass man sich mit der bestehenden Fachliteratur auseinandersetzt und anschliessend neue Zusammenhänge entdeckt, bzw. Forschungslücken schliesst. Eine wichtige Rolle spielen dabei in der Geschichtswissenschaft die Quellen, die verfügbaren zeitgenössischen Unterlagen, welche beispielswiese durch die Öffnung der Archive alleine schon neue Fragestellungen auslösen können.
Grosse Hoffnung: Historische Semantik
In der fachhistorischen Community ist die Aufmerksamkeit gegenüber den Digital Humanities hoch. (1) Die Bewältigung grosser Textmengen ist gerade in der Zeitgeschichte eine grosse Herausforderung, weshalb grosse Hoffnung in die historische Semantik mittels computerlinguistischer Methoden gesetzt werden. Für Textanalysen wird deshalb die Häufigkeit von Begriffen bestimmt (frequency analysis), man könnte aber auch grammatikalische Strukturen untersuchen, was die Begriffsgeschichte wesentlich verfeinern würde. Natürlich bleibt am Ende die Kontextualisierung von Begriffen eine Leistung, welche keiner noch so schlauen Maschine überlassen werden wird. Wir folgen dem Verständnis von Michael Piotrowski in dieser Ausgabe. Piotrowski versteht unter den angewandten Digital Humanities die Anwendung formaler Modelle, ohne dass sich die Fragestellung zur traditionellen Geschichtswissenschaft ändern würde.
Den Wert einer solchen anwendungsorientierten Methodologie soll kurz für die Politikgeschichte skizziert werden. Politikgeschichte – lange etwas stiefmütterlich behandelt – hat sich in jüngerer Zeit als Kulturgeschichte des Politischen erfunden, methodisch geht sie dabei in Richtung historische Semantik. (2) Damit wird die Relevanz politischer Kommunikation deutlich. Die Frage, wie, wo zu welcher Zeit politische Begriffe in Dokumenten auftauchen und mit welchen Absichten die Begriffe in den öffentlichen Diskurs eindringen, ermöglicht neue Erkenntnisse. So baut etwa der Staat in der Nachkriegszeit seine Aktivitäten laufend aus, befeuert durch den Wettbewerb der politischen, gesellschaftlichen und ökomischen Systeme in der Periode des Kalten Kriegs. Nicht nur der Sozialstaat wird in dieser Phase munter ausgebaut, es werden laufend neue Politikfelder kreiert. Oder es wird in einem umfassenden Sinne konzeptionell ein «social engeneering» betrieben, nicht zuletzt im Ringen um den Systemwettbewerb. Beispielhaft wird dies erkennbar im Bereich der Wissenschaftspolitik, wo einerseits der Zugang zu den Hochschulen sowie die staatliche Forschungsförderung ökonomisch legitimiert wird. Dies erfordert von der Politik eine Neubeurteilung der Ausgabenpolitik.
Basis sind maschinenlesbare Texte
Dank eines Digitalisierungsprojektes der Amtsdruckschriften durch das Schweizerische Bundesarchiv stehen der Forschung ortsunabhängig riesige maschinenlesbare Textmengen zur Verfügung aus der Zeit, als die amtlichen Berichte nur gedruckt erschienen waren. Im Bundesblatt werden seit der Gründung des Bundesstaates Botschaften des Bundesrates zu Verfassungs- oder Gesetzesänderungen, zu Volksabstimmungen oder zu anderen Tätigkeiten der Regierung wöchentlich veröffentlicht. Diese Berichte sind seit bald 20 Jahren zugänglich. (3)
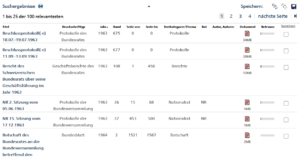
Abbildung: Digitalisierte Amtsdruckschriften des Schweizerischen Bundesarchivs: Suche nach «Wissenschaftspolitik», erste 6 Treffer
Dank dieser digitalisierten (seriellen) Quelle lässt sich eine Begriffsabfrage durchführen. Der Begriff «Wissenschaftspolitik» taucht in Bundesblatt zum ersten Mal 1964 auf (im Jahr zuvor bereits in einem Protokoll des Bundesrates). In dieser Botschaft bittet der Bundesrat das Parlament darum, die Finanzierung der Stiftung Schweizerischer Nationalfonds fortzuführen. An sich handelt es sich um nichts Aussergewöhnliches – Forschungsgelder an den SNF werden seit über zehn Jahren ausgerichtet, doch der Begriff der Wissenschaftspolitik ist neu, was im Dokument selber thematisiert wird. Es heisst dort:
Überall auf der Welt steigt der Finanzbedarf für die Förderung der Forschung und Entwicklung an, und nicht nur die Verantwortlichen für den Staatshaushalt, sondern auch alle grossen Privatunternehmen fragen sich mit Recht, wohin uns der Weg führen wird. Es wird daher allgemein der Ruf nach einer Wissenschafts-Politik erhoben.
Ganz offensichtlich reflektiert die Verwaltung, welche den Text zu Handen von Regierung und Parlament verfasst hat, über das Framing eines Politikfelds. Damit kann – und das ist ja die Aufgabe der Geschichtswissenschaft – eindeutig eine Aussage gemacht werden, dass Mitte der 1960er Jahre ein neuer Begriff in den politischen Diskurs eingeführt wird, der erst noch gewöhnungsbedürftig ist. Ähnlich auch der Begriff «Bildungsinvestition», der fast zeitgleich im Kontext um eine Neuordnung des Stipendienwesens auftaucht. (4) Welches die Hintergründe dieser begrifflichen Neuschöpfungen sind, muss aus den Textquellen selber eruiert werden. Damit ist zwar im Sinne des oben zitierten Beitrags von Piotrowski noch kein Modell für eine digitale Geschichtsschreibung entwickelt, doch der Weg ist nicht mehr weit dazu. Denn durch die Versprachlichung sind Begriffe für das soziale Wissen wirklicher als die materielle Realität. Und deshalb ist es für die Periodisierung – also das Kerngeschäft des Historikers – eminent, genau in Erfahrung zu bringen, wann und in welchem Kontext ein Begriff aus der politischen Kommunikation zum ersten Mal auftaucht.
Referenzen
- Silke Schwandt (2018): Digitale Methoden für die Historische Semantik. Auf den Spuren von Begriffen in digitalen Korpora, in: Geschichte und Gesellschaft – Zeitschrift für Historische Sozialwissenschaft (44/1), S. 107–134.
- Margrit Pernau (2018): (Einführung) Neue Wege der Begriffsgeschichte, in: Geschichte und Gesellschaft – Zeitschrift für Historische Sozialwissenschaft (44/1), S. 5-28.
- Schweizerisches Bundesarchiv: Amtsdruckschriften und weitere digitalisierte Unterlagen
- Allgemein zur Wissenschaftspolitik, vgl. Thomas Gees (2016): Viel Diskurs – wenig Steuerung. Schweizer Wissenschaftspolitik in der Mehrebenenrealität, in Rothen, Christina et al (Hrsg.): Staatlichkeit in der Schweiz Regieren und verwalten vor der neoliberalen Wende, Zürich – Chronos.
 Create PDF
Create PDF


 Beiträge als RSS
Beiträge als RSS