Semantische Suchabfragen mit der Linked Open Data Cloud generieren

“S-O-WAS” – Semantic-and -Ontology-based-Web-Applications-Searchform” erlaubt die maschinengestützte Formulierung von semantischen Suchanfragen in normierten Metadatenfeldern, gezeigt am Beispiel einer Autoren- und Schlagwortsuche mittels Identifikator der Gemeinsamen Normdatei. Unsere AutorInnen haben eine Konzeptstudie während des OpenGLAM.at Kulturhackathons 2018 erarbeitet.
Die zahlreichen und vielfältigen Bestände von Galleries, Libraries, Archives and Museums (GLAM) sind im Laufe von Jahrhunderten entstanden. Die umfangreichen Sammlungen stellen KuratorInnen vor die Aufgabe, geeignete Ordnungsprinzipien zu etablieren und effiziente Suchmöglichkeiten anzubieten. Eine besondere Herausforderung stellen Rechercheanfragen dar, die selbst Ungenauigkeiten bergen oder mit Unbekannten operieren. Dem klassischen enzyklopädischen Weg einer Vorrecherche kann mittels semantischer Suchabfragen aus Linked-Open-Data-Quellen eine moderne Alternative entgegengestellt werden. In Verbindung mit dem in GLAM-Institutionen verbreiteten Einsatz von Normdaten1 zur Beschreibung von geistigen Schöpfern, mitwirkenden Personen und unterschiedlichen Schlagworten können solche Suchabfragen abseits einer potentiell unscharfen Textsuche auch durch den Einsatz von Normdaten-Identifikatoren eine hohe Trefferpräzision erreichen.
Unscharfe Suche in scharfen Metadaten
Die Beschreibung von Bestandsobjekten in GLAM-Institutionen hat eine lange Tradition und baut auf allgemein verbreiteten Regelwerken und Standards auf.2 Diese Metadaten bilden dann bereits einen Textkörper, der dann auch mit Volltextelementen wie Beschreibungen, Abstracts ergänzt werden kann. Die Indexierung der verfügbaren Textbausteine erlaubt eine Textsuche. Die grösste Herausforderung dabei ist die Genauigkeit, die mit Hilfe von Methoden der Informationswissenschaft gemessen wird. Eine der häufig verwendeten Methoden ist, mit dem sogenannten F-Mass sowohl Genauigkeit (precision) als auch Trefferquote (recall) gewichtet zu ermitteln, so dass die Ergebnisliste möglichst wenige unerwünschte Objekte enthält (“false positives”) und andererseits möglichst wenige gewünschte Objekte ausgelassen werden (“false negatives”).
Die Verschlagwortung im speziellen und die Nutzung von Normdaten auch im Bereich formaler Beschreibungen, wie bei den an einem Bestandsobjekt beteiligten Personen, dient nun dem Zweck, diese Genauigkeit bei der Suche zu verbessern. Statt einer rein technischen Extraktion von Wörtern werden diese im inhaltlichen Bereich intellektuell zugewiesen. Das Wort “Logikkalkül” ist dann nicht einfach nur ein Wort, das zufällig im Text auftaucht, sondern es beschreibt einen wissenschaftlichen Themenbereich, der dem Bestandsobjekt (hier beispielsweise ein Buch über Logik) bewusst zugeordnet wird. Ist der Suchbegriff Teil der Schlagwortliste, so liegt es nahe, die Relevanz gegenüber den Objekten, die den Begriff nur beinhalten, höher einzustufen. In formalen Fragen helfen Normdateien bei der Suche nach Personen, diese eindeutig, trotz häufig vorkommender vollständig identer Namen zu unterscheiden und die Genauigkeit der Recherche zu erhöhen.
Das Semantic Web hilft
In vielen GLAMs wird die manuelle Verschlagwortung durch eine wachsende Anzahl von Einzelobjekten zunehmend schwieriger. In den Bibliotheken betrifft dies vor allem die neuen Netzpublikationen3 , die aus diesem Grund zunehmend mit maschineller Unterstützungen verschlagwortet werden (Faden und Gross 2010; Hinrichs et al. 2016). Eine der grössten Herausforderungen der automatisierten Verschlagwortung ist dabei, eine mit der manuellen Verschlagwortung vergleichbare Qualität zu erreichen.
Das Ziel der hier vorgestellten Überlegungen ist es, die manuell vergebenen, aber normierten Metadaten für eine präzise Suche in den Beständen der GLAMs zu nutzen. Mit Hilfe von Semantic Web Suchtechnologien und auf der Basis der in der Linked-Open-Data-Cloud verfügbaren Daten wird zunächst eine Suche nach Personen durchgeführt, die anschliessend mit einer Suche im Bestandskatalog nach Einzelobjekten auf der Basis manuell vergebener Schlagworte verknüpft wird. Bibliotheken, Sammlungen, Archive und Museen können auf diese Weise das Potential ihrer Metadaten, wie beispielsweise der manuell und aufwändig vergebenen Schlagworte, besser nutzen und mit Hilfe des Werkzeugs “S-O-WAS” ihrem Publikum eine semantische Suche ermöglichen.
Zur Ermöglichung einer semantischen Suche soll zunächst der Informationsreichtum der Linked Open Data Cloud genutzt werden. Insbesondere steht dabei die freie Wissensdatenbank Wikidata4 im Vordergrund, die eine umfangreiche Sammlung von Objekten beinhaltet, die das Wissen in Form von Aussagen und Fakten über diese Objekte strukturiert. Um die Nutzung der Wissensdatenbank zu ermöglichen, stellt Wikidata unter anderem eine Schnittstelle für die Abfrage der Daten mit der Abfragesprache SPARQL5 bereit.
Die Funktionsweise der Abfrage wird im Folgenden anhand eines konkreten Beispiels erläutert.
Semantische Suche nach Personen
Nehmen wir zum Beispiel an, es wird nach einer Person gesucht, die bestimmte Kriterien erfüllen soll. Der Name der Person sei zunächst nicht bekannt. Zum Einen wissen wir, dass die Person ein Autor (männlich) ist, was jedoch zunächst keine Rolle spielt. Wir wissen, dass diese Person im 19. Jahrhundert geboren wurde, in Grossbritannien lebte und von Beruf Mathematiker war. Das Venn-Diagramm in Abbildung 1 veranschaulicht die Einschränkung auf eine diesen Kriterien entsprechende Schnittmenge.

Abbildung 1: Person, lebte in Grossbritannien, geboren im 19. Jahrhundert, Mathematiker.
Allein mit Hilfe dieser Kriterien lässt sich eine semantische Abfrage formulieren, die als Ergebnis eine Liste der Personen zurückliefert, die den Kriterien entsprechen:
- SELECT DISTINCT ?Person ?PersonLabel ?GND WHERE {
- SERVICE wikibase:label { bd:serviceParam wikibase:language «(AUTO_LANGUAGE),en». }
- ?Person wdt:P27 wd:Q145.
- ?Person wdt:P569 ?Gebdatum.
- ?Person wdt:P21 wd:Q6581097.
- ?Person wdt:P227 ?GND.
- ?Person (wdt:P106/wdt:P279*) ?Beruf. FILTER(?Beruf IN(wd:Q14565331, wd:Q4964182)). FILTER NOT EXISTS {?Person wdt:P106 wd:Q49757. } FILTER((YEAR(?Gebdatum)) >= 1800)
- FILTER((YEAR(?Gebdatum)) < 1900) }
Betrachten wir zum Beispiel einen Teil der Abfrage, der die Abfragekriterien enthält: ?Person wdt:P27 wd:Q145.
Es wird ersichtlich, dass nicht die Bezeichner selbst, sondern Identifier für Objekte (beginnend mit “Q”) und Prädikate (beginnend mit „P“) verwendet werden. In diesem Teil der Abfrage bezieht sich ?Person auf die gesuchte Entität, die in der ersten Zeile als Variable definiert wurde, Q145 referenziert das Objekt “United Kingdom” und P106 repräsentiert das Prädikat “country of citizenship”. Die Eigenschaften von Objekten und Prädikaten (z.B. Bezeichner in anderen Sprachen) können auf der Wikidata-Seite zum Objekt (hier Q1456) oder zum Prädikat (hier P1067) eingesehen werden.
Das Ergebnis8 der Abfrage ist (erstellt am 26. September 2018) eine Liste von 71 Personen, beginnend mit den folgenden 4 Personen:
| Wikidata-ID | Personenname (WikidataLabel) | GND-ID |
| 1. wd:Q334846 | Edmund Allenby, 1st Viscount Allenby | 119161311 |
| 2. wd:Q722472 | Homer H. Dubs | 11623167X |
| 3. wd:Q725050 | John Burnet | 117175056 |
| 4. wd:Q310794 | Karl Pearson | 118982141 |
Dieses Ergebnis diente der vorläufigen Einschränkung des Suchraumes mit Hilfe logisch-semantischer Bedingungen. Im Folgenden wird gezeigt, wie dieses Ergebnis mit Hilfe einer konkreten Abfrage in Bezug auf Bestandsobjekte von GLAMs bzw. hier konkret in Bezug auf Werke einer Bibliothek genutzt werden kann.
Suche nach Unterbegriffen
Im letzten Abschnitt haben wir ein Suchbeispiel vorgestellt, in welchem nach einer Person gesucht wird. Stellen wir uns nun vor, dass wir spezifischer nach einem Autor suchen, der ein Werk verfasst hat, das inhaltlich im Feld der Logik angesiedelt ist, und dass wir aufgrund der Spezialisierung davon ausgehen können, dass eines der in relevanten Werken vergebenen Schlagworte ein Unterbegriff von Logik (z.B. Aussagenlogik, Prädikatenlogik, etc.) ist. Im deutschen Sprachraum findet die sogenannte Gemeinsame Normdatei (GND) verbreitet Anwendung. Diese ist nicht nur eine Begriffssammlung, sondern stellt zugleich auch eine Ontologie dar. Diese ermöglicht es uns beispielsweise innerhalb der Sachschlagwörter der GND nach über- oder untergeordneten Begriffen zu recherchieren. Mit der Plattform lobid.org steht eine frei nutzbare REST-API9 zur Verfügung, die es erlaubt, die GND maschinenlesbar abzufragen. Dies ermöglicht bei Kenntnis der Feldstruktur eines indexierten Dokumentes, den Aufbau komplexer Suchabfragen durch Eingabe der jeweiligen Feld-/”Spalten”namen.10
Die Suche nach Sachschlagwörtern, deren übergeordneter Begriff Logik ist, hat als HTTP-Request die folgende Form: http://lobid.org/gnd/search?q=type%3ASubjectHeading+AND+broaderTermGener%20al.label%3ALogik&format=json&size=120
An die REST-Schnittstelle von lobid.org werden hier drei Paramter übergeben:
- q: übergibt die eigentliche Suchabfrage.
- type=SubjectHeading – sucht nach GND-Einträgen die Sachschlagwörter darstellen
- broaderTermGeneral.label=Logik sucht nach Einträgen deren übergeordneter Begriff Logik enthält.
- format: definiert das auszugebende Format des Ergebnisses
- size: Anzahl der zurückgegebenen Treffer einer Anfrage
Aus dem Ergebnis kann für die weiterführende Suche im Zielkatalog je nach Sinnhaftigkeit und Einsatzmöglichkeit der Identifier des Begriffes oder aber auch die Ansetzungsform des Schlagwortes verwendet werden.
Verknüpfung der Personen- mit der Schlagwortsuche
Die in den beiden zuvor gezeigten Schritten maschinenlesbar gewonnen Ergebnisse erlauben nun die anfänglich unscharfe Suchabfrage in Form eines Suchbefehls zu bringen, der die einzelnen Schlagwörter mit den jeweiligen Autoren kombiniert, idealerweise sogar ausschliesslich durch die Verwendung von Identifikatoren der im Zielkatalog der Institution eingesetzten Normdatei.
Eine Voraussetzung für die Implementierung ist, dass für die in den Bestandsmetadaten existierenden Schlagworte die entsprechenden GND Identifier angereichert werden. Bezüglich der methodisch vergebenen Sachschlagwörter kann eine eindeutige Zuweisung durch die Lobid-Abfrage erreicht werden. Kommen jedoch frei vergebene Schlagworte oder Personennamen hinzu, so müssen die Terme eventuell durch Hinzuziehen vonKontext-Informationen disambiguiert werden. Die Anreicherung der Metadaten mit Schlagwort-GND-Identifiern kann unabhängig von der späteren Abfrage auf dem gesamten Metadatenbestand im Vorhinein durchgeführt werden.
In Abbildung 2 wird der Ablauf beginnend von der Formulierung der Suchanfrage bis zur Ergebnisdarstellung schematisch dargestellt. Der horizontale Querbalken im unteren Bereich der Grafik stellt die Systemgrenze dar. Die oder der BenutzerIn formuliert eine Abfrage mit den semantischen Bedingungen und dem konkreten Begriff zu einem Sachgebiet.
Der QueryBuilder ist eine Komponente, die aus der Suchanfrage die Systemanfragen sowohl an die lobid-API als auch an Wikidata generiert.
Die Semantische Abfrage wird als SPARQL-Abfrage an die Wikidata geschickt (Schritt 1a und 2a in Abbildung 2), die als Ergebnis die Menge der Wikidata-Identifier IP der Menge der Personen P=(p1, p2, …, pn) liefert, die den semantischen Kriterien entsprechen.
IP=(gndp1, gndp2, …, gndpn)
Im ersten Schritt wird die Menge der GND-Identifier I der Unterbegriffe Us=(u1, u2, …, un) zum Themengebiet s (in diesem Beispiel s=»Logik») mit Hilfe der lobid-API in Form einer REST-Abfrage ermittelt (Schritt 1b und 2b in Abbildung 2).
IUs=(gndu1, gndu2, …, gndun)
Unter der Voraussetzung, dass in den Metadaten eines Bestandsobjekts r die GND-Identifier IAr für Personen (=AutorInnen) und die GND-Identifier ISr für Sachschlagworte zugewiesen sind, ist die Ergebnismenge R=(r1, r2, …, rn) der Bestandsobjekte dadurch definiert, dass mindestens ein Autor ip unter den Autoren schlagworten IAr und mindestens ein Unterbegriff iu unter den Schlagworten ISr in den Metadaten des Bestandsobjekts vorhanden sein muss (Schritt 3 und 4 in Abbildung 2):
R = {r | Ǝ ip ∈ IAr ∧ Ǝ iu ∈ ISr r}
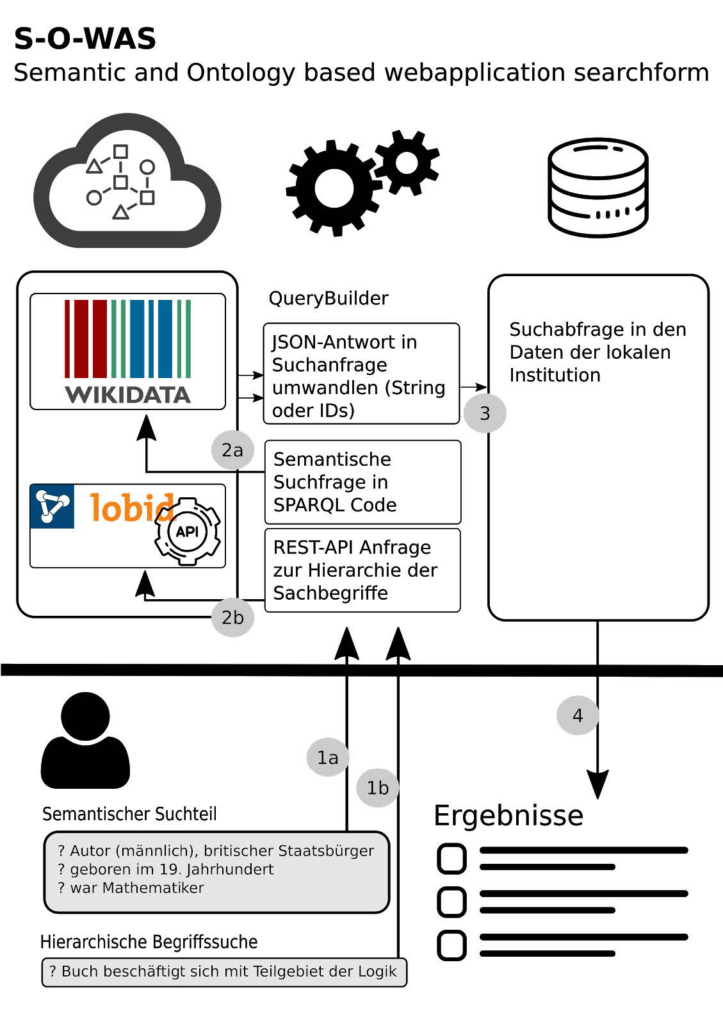
Abbildung 2: Schema der Generierung eine Suchmaschine mittels Linked Open Data Quellen
Verwandte Arbeiten
Die Verwendung von Wikidata zur Community-basierten Zuordnung von Namen und anderen Entitäten aus Normdateien wurde von Joachim Neubert vorgestellt (Neubert, 2017). Der wesentliche Unterschied ist, dass die externen Identifier selbst, die eine Organisation verwaltet, in die Wikidata integriert werden. Auf diese Weise können dann Links zurück auf das Bestandsobjekt im Katalog generiert werden (Lemus-Rojas et al., 2018).
Ausblick
Die während des zweiten openglam.at Kulturhackathons 201811 entstandenen und hier dargestellten konzeptuellen Überlegungen zeigen die Innovationspotentiale von Linked Open Data (LOD) in GLAM-Institutionen auf, und zwar in der Verbindung zwischen externen LOD-Quellen und lokalen, klassischen textbasierten Suchmöglichkeiten der jeweiligen Institutionen. Letztere haben durch ihre langjährige Erfahrung und den Einsatz normierter Datenbestände wie der gemeinsamen Normdatei (und ihrer Vorgängerkorpora) eine nicht zu unterschätzende Grundlage für die Kopplung an moderne Open Data Tools geschaffen.
Die freie Wissensdatenbank Wikidata erlaubt mit SPARQL auch komplexe Anfrage formulieren zu können und bietet die Möglichkeit GND-IDs als Antwort zu senden. Mit der freien Plattform lobid.org/gnd kann die GND selbst auf simple Art und Weise auch in ihrer Ontologie maschinenlesbar durchsucht werden. Eine Query-Builder-Applikation steuert entsprechende Anfragen und bereitet diese vor, kombiniert die aus LOD-Cloud stammenden Antworten und baut eine Suchabfrage an den lokalen Bestandskatalog vor.
Referenzen
1 Für den deutschen Sprachraum bildet die gemeinsame Normdatei (http://www.dnb.de/DE/Standardisierung/GND/gnd_node.html) einen weitverbreiten Standard.
2 Im Bibliotheksbereich gelten beispielsweise für die formale Katalogisierung RDA (Ressource Description and Access) oder RAK (Regeln für den alphabetischen Katalog) oder für die inhaltlichen Beschreibung RSWK (Regeln für den Schlagwortkatalog).
3 Bei der Deutschen Nationalbibliothek: Reihe O: http://www.dnb.de/DE/Service/DigitaleDienste/DNBBibliografie/reiheO.html
5 https://www.w3.org/TR/rdf-sparql-query/
6 https://www.Wikidata.org/wiki/Q145
7 https://www.Wikidata.org/wiki/Property:P27
8 Ergebnis in Echtzeit abrufbar unter: http://tinyurl.com/y7l3wh4n
10 Aufbau erweiterter Suchabfragen übersichtlich erklärt: http://blog.lobid.org/2018/07/06/lobid-gnd-queries.html
Weiterführende Literatur
Faden, Manfred; Gross, Thomas: Automatische Indexierung elektronischer Dokumente an der Deutschen Zentralbibliothek für Wirtschaftswissenschaften. In: Bibliotheksdienst 44 (2010), Nr. 12, S. 1120 – 1135.
Hinrichs, I., Milmeister, G., Schäuble, P., & Steenweg, H. (2016). Computerunterstützte Sacherschliessung mit dem Digitalen Assistenten (DA-2). O-Bib. Das Offene Bibliotheksjournal / Herausgegeben Vom VDB, 3(4), 156-185.
Neubert, J. Wikidata as a Linking Hub for Knowledge Organization Systems? Integrating an Authority Mapping into Wikidata and Learning Lessons for KOS Mappings NKOS@TPDL, CEUR-WS.org, 2017, 1937, 14-25.
Lemus-Rojas, M., Pintscher, L. (2018). Wikidata and Libraries: Facilitating Open Knowledge. In M. Proffitt (Ed.), Leveraging Wikipedia: Connecting Communities of Knowledge (pp. 143-158). Chicago, IL: ALA Editions.

![]() Christian Erlinger-Schiedlbauer ist Systembibliothekar bei den Büchereien Wien und Wikidata-Enthusiast.
Christian Erlinger-Schiedlbauer ist Systembibliothekar bei den Büchereien Wien und Wikidata-Enthusiast.
![]() Georg Neubauer arbeitet an der Donau-Universität Krems. Seine Expertisen sind InfoVis, GrafikDesign und e-resource management.
Georg Neubauer arbeitet an der Donau-Universität Krems. Seine Expertisen sind InfoVis, GrafikDesign und e-resource management.
![]() Bernhard Spangl arbeitet als Statistiker an der Universität
Bernhard Spangl arbeitet als Statistiker an der Universität
für Bodenkultur Wien.
![]() Alexander Rind forscht an der FH St. Pölten. Er forscht an Methoden der Informationsvisualisierung und Visual Analytics, um die Analyse heterogener zeit-orientierter Daten in menschlichen Arbeits- und Lebenskontexte besser einzubetten.
Alexander Rind forscht an der FH St. Pölten. Er forscht an Methoden der Informationsvisualisierung und Visual Analytics, um die Analyse heterogener zeit-orientierter Daten in menschlichen Arbeits- und Lebenskontexte besser einzubetten.
![]() Sven Schlarb forscht beim AIT Austrian Institute of Technology in Europäischen und Österreichischen Forschungsprojekten. Er arbeitet mit umfangreichen digitalen Sammlungen in Archiven und Bibliotheken. Er interessiert sich besonders für Technologien zur Verarbeitung natürlicher Sprache und die Repräsentation von Semantik in Dokumentenmanagement- und Informationssystemen.
Sven Schlarb forscht beim AIT Austrian Institute of Technology in Europäischen und Österreichischen Forschungsprojekten. Er arbeitet mit umfangreichen digitalen Sammlungen in Archiven und Bibliotheken. Er interessiert sich besonders für Technologien zur Verarbeitung natürlicher Sprache und die Repräsentation von Semantik in Dokumentenmanagement- und Informationssystemen.
![]() Sylvia Petrovic-Majer arbeitet als selbstständige Projektleiterin OpenGLAMat und in der Unternehmenskommunikation der FH St. Pölten.
Sylvia Petrovic-Majer arbeitet als selbstständige Projektleiterin OpenGLAMat und in der Unternehmenskommunikation der FH St. Pölten.

 Beiträge als RSS
Beiträge als RSS
Dein Kommentar
An Diskussion beteiligen?Hinterlasse uns Deinen Kommentar!