Intelligente Prozessdekomposition: Ein pragmatischer Ansatz zur BPMN-Generierung
Im ersten Artikel dieser Reihe haben wir gezeigt, warum aktuelle Sprachmodelle keine zuverlässigen BPMN-Diagramme erzeugen können. Strukturelle Komplexität, Kontextfenster-Grenzen, Nichtdeterminismus und Layout-Anforderungen machen eine einfache Einzelgenerierung zum Scheitern verurteilt. Aber diese Hürden lassen sich systematisch überwinden. Wir haben einen ersten Prototyp entwickelt, der mit aktueller Technologie funktioniert.
Das Problem mit der Spezifikationsüberlast
LLMs brauchen BPMN-Spezifikationswissen, um gültige Diagramme zu erzeugen. Die vollständige BPMN-2.0-Spezifikation in jeden Prompt zu laden ist aber unpraktisch: Es erhöht Kosten und Latenz, verbraucht Token-Budget und lässt weniger Raum für die eigentliche Prozessbeschreibung. Ausserdem verlieren Modelle Informationen aus der Mitte langer Kontexte, was zu Fehlern führt.
Unser Ansatz: eine dedizierte Wissensdatenbank mit kuratierten BPMN-Extrakt-Fragmenten. Statt das gesamte Regelwerk mitzuliefern, fragt das System zur Laufzeit nur jene Fragmente ab, die für die konkrete Anfrage relevant sind. Dieses Prinzip überträgt Retrieval-Augmented Generation (RAG) auf die strukturierte Artefaktgenerierung (Gao et al., 2023). Das Ergebnis: präzise kalibrierte Prompts mit dem nötigen Wissen, ohne unnötige Last.
Komplexität und Architektur aufeinander abstimmen
Nicht alle Prozesse stellen dieselben Anforderungen. Einfache Abläufe lassen sich direkt generieren. Komplexe Prozesse benötigen eine durchdachte Dekomposition. Alles durch ein einziges Muster zu zwingen verschwendet Ressourcen oder liefert schlechte Ergebnisse.
Wir haben ein adaptives Komplexitäts-Routing implementiert, das eingehende Prozessbeschreibungen anhand logischer Prozessblöcke bewertet und einem von zwei Verarbeitungspfaden zuweist:
- Direkter-Pfad (≤3 logische Prozesse): Einfache Prozesse werden direkt generiert. Ein umfassender Prompt mit Prozessbeschreibung, relevanten BPMN-Elementen aus der Wissensdatenbank und Generierungsanweisungen reicht aus, damit das Modell ein vollständiges Diagramm in einem Durchlauf erstellt.
- Orchestrations-Pfad (>3 logische Prozesse): Komplexe Prozesse durchlaufen eine mehrstufige Pipeline, koordiniert über LangChain. Die Aufgabe wird dabei in spezialisierte Teilschritte zerlegt. Das Aufteilen in Teilaufgaben erhöht die Präzision und entspricht gängigen Reasoning- Architekturen (Anthropic, 2023).
Das Routing verhindert beide Extreme: keine schwere Orchestrierungsinfrastruktur für einfache Fälle, aber ausreichend Struktur für komplexe Workflows.
Die Orchestrierungspipeline für komplexe Prozesse
Für komplexe Prozesse setzt das System eine koordinierte Pipeline mit drei spezialisierten Stufen ein.
Prozessanalyse: Ein ProcessAnalyzer empfängt die natürlichsprachliche Beschreibung und fragt die Wissensdatenbank ab, um alle relevanten BPMN-Elemente und deren Verbindungen zu identifizieren. Das Ergebnis ist eine strukturierte Repräsentation mit Teilprozessgrenzen, Teilnehmern, Gateway-Typen und Event-Triggern. Entscheidend ist die Zerlegung des Gesamtprozesses in handhabbare Teilprozesse, die jeweils zuverlässig ins Kontextfenster passen.
Teilprozess-Generierung: Einzelne SubprocessGenerators bearbeiten jeden Teilprozess unabhängig und erhalten fokussierten Kontext über ihren spezifischen Abschnitt. Jeder Generator produziert gültiges BPMN-XML für seinen Teilprozess innerhalb zuverlässiger Kontextfenster-Grenzen. Diese Dekomposition adressiert direkt die Kontext-Limitierungen, die bei der Einzelpass-Generierung komplexer Prozesse scheitern.
Integration und Validierung: Ein Subprocess-Integrator fügt das vollständige Diagramm zusammen, stellt korrekte Verbindungen zwischen Teilprozessen sicher, verwaltet konsistente Element-IDs und gewährleistet eine valide Gesamtstruktur. Validatoren prüfen syntaktische Korrektheit, semantische Konformität und Layout-Qualität. Bei häufigen Problemen versucht das System eine automatische Reparatur vor der finalen Ausgabe.
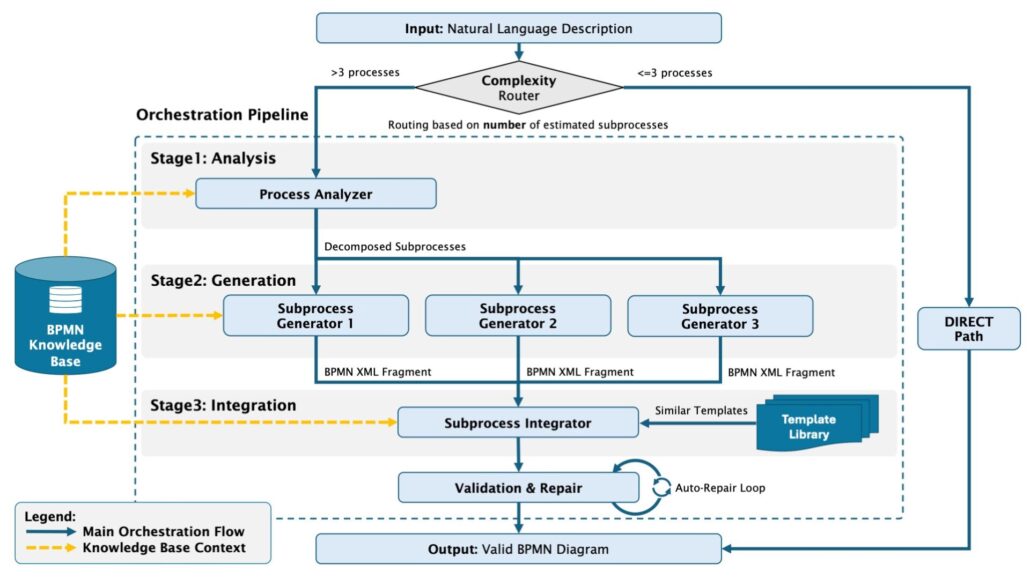
Template-basierte Verfeinerung durch Ähnlichkeitsabgleich
Spezifikationswissen allein reicht nicht aus, um Layouts zu generieren, die professionellen Standards entsprechen. Wir ergänzen dies darum mit einem embedding-basierten Template-Retrieval.
Das System pflegt dabei eine Bibliothek validierter BPMN-Diagramme mit den Beschreibungen, die sie hervorgebracht haben. User-Beschreibungen werden in einer Vektordatenbank eingebettet und zusammen mit Referenzen auf entsprechende gültige BPMN-Ausgaben gespeichert. Bei neuen Prozessbeschreibungen ruft das System semantisch ähnliche historische Beschreibungen ab und übergibt die zugehörigen BPMN-Templates an den Integrator mit der Anweisung wie: „Das ist ein strukturell ähnlicher Prozess, passe dieses Template an die aktuellen Anforderungen an.“
Der Ansatz verbindet Spezifikationswissen mit konkreten Beispielen professionell valider Ausgaben. Das reduziert logische und visuelle Fehler, verbessert die Einhaltung von Layout-Konventionen und beschleunigt die Generierung bei Prozessen, die bereits gelösten Fällen ähneln.
Potenzial und Forschungsrichtungen
Dieser Ansatz adressiert die praktischen Einschränkungen, die die Einzelgenerierung limitieren:
- Spezifikationspräzision ohne (Über-) Last: Wissensdatenbank-Abfragen liefern Präzision, ohne Prompts aufzublähen oder Kontextfenster zu überlasten.
- Architektonische Flexibilität: Komplexitäts-Routing verhindert Übertechnisierung einfacher Fälle und stellt sicher, dass komplexe Prozesse ausreichend Struktur erhalten.
- Qualität durch Beispiele: Template-Retrieval bringt professionell-standardkonforme Ausgaben in Reichweite, ohne umfangreiche Spezifikationsprompts oder manuelle Nachbearbeitung.
Die Integration von Wissensdatenbanken, Komplexitäts-Routing, spezialisierten Agenten und Fallbibliotheken ist ein methodischer Paradigmenwechsel. Statt zu fragen „Wie kann ein einzelnes Modell BPMN besser verstehen?“ fragen wir: „Wie können wir Modelle systematisch mit dem genauen Wissen, der Struktur und den Beispielen versorgen, die sie brauchen?“
Diese Perspektive legt nahe, dass zuverlässige automatisierte Diagrammgenerierung weniger von fundamentalen LLM-Verbesserungen abhängt als von durchdachtem Knowledge Engineering. Die aktuelle Implementierung zeigt Machbarkeit für einfache und mässig komplexe Prozesse, mit laufenden Arbeiten, die substantielles Potenzial für produktionsreife Generierung zeigen.
Referenzen
Anthropic. (2023). Question decomposition improves the faithfulness of model-generated reasoning. https://www.cdn.anthropic.com/8154fb1d828cdc390dc1fa442d84034948679c47/question-decomposition-improves-the-faithfulness-of-model-generated-reasoning.pdf
Gao, Y., et al. (2023). Retrieval-augmented generation for large language models: A survey. arXiv. https://arxiv.org/pdf/2312.10997
LangChain. (n.d.). LangGraph overview. LangChain documentation. Retrieved January 14, 2026, from https://docs.langchain.com/oss/python/langchain/overview#langgraph

![]() Moritz Maier ist Tenure-Track-Professor für Prozessanalyse und Digitalisierung am Institut für Datenanwendungen und Sicherheit (IDAS) innerhalb des Departements Technik und Informatik der Berner Fachhochschule.
Moritz Maier ist Tenure-Track-Professor für Prozessanalyse und Digitalisierung am Institut für Datenanwendungen und Sicherheit (IDAS) innerhalb des Departements Technik und Informatik der Berner Fachhochschule.
![]() Maksym Hudynovich ist Software Engineer an der BFH.
Maksym Hudynovich ist Software Engineer an der BFH.
![]() Stefan Grösser ist Professor für Decision Sciences and Policy und leitet die Forschungsgruppe zu Management Science, Innovation and Sustainability an der BFH Technik & Informatik. Er doziert im Master of Engineering (MSE) und arbeitet in mehreren Forschungsprojekten in den Bereichen Simulationsmethodik (System Dynamics, Agent-based Modelling, Machine Learning), Entscheidungsfindung unter Verwendung künstlicher Intelligenz (Decision Making and Management Science), Kreislaufwirtschaft (Circular Economy, Circular Business Models). Seine Industrien sind insbesondere die Solar-, Energie- und Gesundheitsbranche. Des Weiteren mit Beiträgen zu modernen Lerntechnologien.
Stefan Grösser ist Professor für Decision Sciences and Policy und leitet die Forschungsgruppe zu Management Science, Innovation and Sustainability an der BFH Technik & Informatik. Er doziert im Master of Engineering (MSE) und arbeitet in mehreren Forschungsprojekten in den Bereichen Simulationsmethodik (System Dynamics, Agent-based Modelling, Machine Learning), Entscheidungsfindung unter Verwendung künstlicher Intelligenz (Decision Making and Management Science), Kreislaufwirtschaft (Circular Economy, Circular Business Models). Seine Industrien sind insbesondere die Solar-, Energie- und Gesundheitsbranche. Des Weiteren mit Beiträgen zu modernen Lerntechnologien.
 Beiträge als RSS
Beiträge als RSS
Dein Kommentar
An Diskussion beteiligen?Hinterlasse uns Deinen Kommentar!