Décomposition Intelligente des Processus : Une Approche Pragmatique pour la Génération de BPMN
Dans notre article précédent, nous avons expliqué pourquoi les modèles de langage (LLM) peinent à générer des diagrammes BPMN valides. Les défis sont nombreux : complexité structurelle, limitations de contexte, décalage entre connaissance et exécution, non-déterminisme et problèmes de mise en page.
Cependant, ces défis peuvent être surmontés. Nous avons développé un prototype fonctionnant avec la technologie actuelle en traitant systématiquement chaque limitation.
Le Problème de la Surcharge de Spécifications
Les LLM ont besoin de connaissances sur la spécification BPMN pour générer des diagrammes valides. Intégrer l’ensemble de la spécification BPMN 2.0 dans chaque prompt crée une surcharge importante, augmentant les coûts, la latence et la consommation de tokens, tout en réduisant l’espace disponible pour la description réelle des processus. Les modèles peinent également à retenir l’information dans des contextes longs, rendant les prompts massifs impraticables.
Nous avons résolu ce problème grâce à une stratégie basée sur une base de connaissances. Au lieu d’intégrer toute la documentation BPMN dans le prompt, nous maintenons une base de connaissances dédiée contenant des extraits sélectionnés : éléments valides, règles et contraintes des éléments, et directives de mise en page.
Au moment de la génération, le système interroge cette base pour récupérer uniquement les fragments nécessaires à la requête spécifique. Cette approche applique les principes du Retrieval-Augmented Generation (RAG) (Gao et al., 2023) à la connaissance fondamentale nécessaire à la génération des artefacts. Le résultat : des prompts calibrés contenant uniquement les connaissances requises, sans surcharge inutile.
Adapter la Complexité aux Capacités
Tous les processus ne nécessitent pas la même architecture. Les workflows simples requièrent une génération directe, tandis que les processus complexes nécessitent une décomposition sophistiquée. Appliquer un seul modèle à tous les processus gaspille des ressources et peut produire des résultats médiocres.
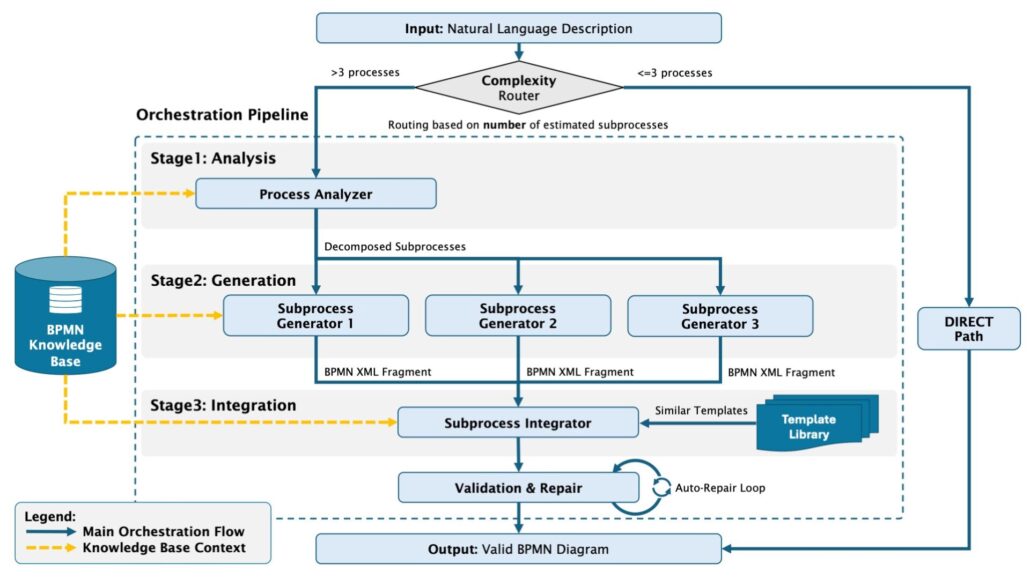
Nous avons implémenté une routage adaptatif en fonction de la complexité, qui évalue les descriptions de processus entrantes en fonction de leurs blocs logiques. Cela détermine lequel des deux chemins de traitement est le plus approprié :
Chemin DIRECT (≤ 3 processus logiques) : Les processus simples sont générés directement. Le système utilise un prompt unique comprenant la description de l’utilisateur, les éléments BPMN pertinents de la base de connaissances et les instructions de génération. Cela fournit un contexte suffisant pour une génération en un seul passage, évitant une architecture inutile.
Chemin ORCHESTRATION (> 3 processus logiques) : Les processus complexes suivent un pipeline multi-étapes coordonné via LangChain. Les tâches sont décomposées en étapes spécialisées, conformément aux résultats montrant que diviser les questions en sous-tâches améliore la fidélité du raisonnement du modèle (Anthropic, 2023).
Ce routage évite les deux extrêmes : les cas simples échappent à une orchestration lourde, tandis que les processus complexes reçoivent un traitement approprié.
Pipeline d’Orchestration pour les Processus Complexes
Pour les processus complexes, le système utilise un pipeline en trois étapes :
- Analyse du Processus : Un ProcessAnalyzer reçoit la description en langage naturel et interroge la base de connaissances pour identifier les éléments BPMN pertinents et leurs interconnexions. Il produit une représentation structurée, identifiant les limites des sous-processus, les participants requis, les types de gateways et les déclencheurs d’événements. Critiquement, il décompose les processus complexes en sous-processus gérables, adaptés aux fenêtres de contexte fiables.
- Génération des Sous-Processus : Des SubprocessGenerators individuels traitent chaque sous-processus de manière indépendante, recevant un contexte ciblé pour leur portion du processus global. Chaque générateur produit un XML BPMN valide pour son sous-processus, respectant les limites de contexte pour garantir une attention fiable. Cette décomposition résout les limitations des fenêtres de contexte qui empêchent la génération en un seul passage pour des processus complexes.
- Intégration et Validation : Un Subprocess Integrator assemble le diagramme complet, assurant des connexions correctes, des identifiants cohérents et une structure globale valide. Des validateurs vérifient la syntaxe, la conformité sémantique et la qualité de la mise en page. Les problèmes courants sont corrigés automatiquement avant la sortie finale.
Aperçu de notre modèle:
Raffinement Basé sur des Modèles par Similarité
La connaissance de la spécification seule ne garantit pas une mise en page conforme aux standards professionnels. Nous utilisons le récupération de modèles basée sur l’embedding.
Le système maintient une bibliothèque de cas de diagrammes BPMN validés, associés aux descriptions qui les ont générés. Les descriptions des utilisateurs sont intégrées dans une base vectorielle avec les références aux diagrammes BPMN correspondants. La recherche montre que fournir des démonstrations structurellement similaires est crucial pour un apprentissage efficace.
Lorsqu’une nouvelle description de processus est soumise, le système l’intègre, récupère des descriptions historiques sémantiquement proches et transmet les modèles BPMN correspondants à l’intégrateur. Ce dernier fonctionne en mode adaptation : « Il s’agit d’un processus structurellement similaire ; adaptez ce modèle aux exigences actuelles. »
Cette approche combine la connaissance de la spécification avec des exemples concrets de sorties valides et de qualité professionnelle. Les bénéfices incluent une réduction des erreurs logiques et visuelles, une meilleure conformité aux conventions de mise en page et une génération plus rapide pour les processus similaires à des cas déjà résolus.
Potentiel et Pistes de Recherche
Cette approche augmentée par base de connaissances et routée en fonction de la complexité répond aux contraintes pratiques limitant la génération en un seul passage :
- Précision de la spécification sans surcharge : Les requêtes à la base de connaissances offrent une précision sans gonfler les prompts ni saturer les fenêtres de contexte.
- Flexibilité architecturale : Le routage de la complexité évite la sur-ingénierie pour les cas simples et assure un traitement adéquat pour les processus complexes.
- Qualité par les exemples : La récupération de modèles fournit des résultats conformes aux standards professionnels sans nécessiter de prompts exhaustifs ni de raffinements manuels importants.
L’intégration de bases de connaissances, de routage par complexité, d’agents spécialisés et de bibliothèques de cas représente un changement méthodologique. Plutôt que de demander « Comment un modèle unique peut-il mieux comprendre BPMN ? », nous demandons « Comment fournir systématiquement aux modèles les connaissances, la structure et les exemples précis dont ils ont besoin ? »
Cette approche suggère que la génération automatisée fiable de diagrammes dépend moins des améliorations fondamentales des LLM que de l’ingénierie avancée des connaissances. L’implémentation actuelle démontre la faisabilité pour des processus simples et modérément complexes, avec un potentiel significatif pour la génération de qualité production.
Références
Anthropic. (2023). Question decomposition improves the faithfulness of model-generated reasoning. https://www.cdn.anthropic.com/8154fb1d828cdc390dc1fa442d84034948679c47/question-decomposition-improves-the-faithfulness-of-model-generated-reasoning.pdf
Gao, Y., et al. (2023). Retrieval-augmented generation for large language models: A survey. arXiv. https://arxiv.org/pdf/2312.10997
LangChain. (n.d.). LangGraph overview. LangChain documentation. Retrieved January 14, 2026, from https://docs.langchain.com/oss/python/langchain/overview#langgraph

![]() Moritz Maier est professeur en tenure track pour l’analyse des processus et la numérisation à l’Institut des applications et de la sécurité des données (IDAS), rattaché au Département de technologie et d’informatique de la Haute école spécialisée bernoise (BFH).
Moritz Maier est professeur en tenure track pour l’analyse des processus et la numérisation à l’Institut des applications et de la sécurité des données (IDAS), rattaché au Département de technologie et d’informatique de la Haute école spécialisée bernoise (BFH).
![]() Maksym Hudynovich est ingénieur logiciel à la BFH.
Maksym Hudynovich est ingénieur logiciel à la BFH.
![]() Stefan Grösser est professeur en sciences décisionnelles et politiques et dirige le groupe de recherche en sciences de gestion, innovation et durabilité à la BFH Technique & Informatique. Il enseigne dans le cadre du Master of Engineering (MSE) et travaille sur plusieurs projets de recherche dans les domaines de la méthodologie de simulation (dynamique des systèmes, modélisation basée sur les agents, apprentissage automatique), de la prise de décision à l'aide de l'intelligence artificielle (prise de décision et sciences de gestion) et de l'économie circulaire (économie circulaire, modèles commerciaux circulaires). Il s'intéresse en particulier aux secteurs de l'énergie solaire, de l'énergie et de la santé. Il contribue également à des publications sur les technologies d'apprentissage modernes.
Stefan Grösser est professeur en sciences décisionnelles et politiques et dirige le groupe de recherche en sciences de gestion, innovation et durabilité à la BFH Technique & Informatique. Il enseigne dans le cadre du Master of Engineering (MSE) et travaille sur plusieurs projets de recherche dans les domaines de la méthodologie de simulation (dynamique des systèmes, modélisation basée sur les agents, apprentissage automatique), de la prise de décision à l'aide de l'intelligence artificielle (prise de décision et sciences de gestion) et de l'économie circulaire (économie circulaire, modèles commerciaux circulaires). Il s'intéresse en particulier aux secteurs de l'énergie solaire, de l'énergie et de la santé. Il contribue également à des publications sur les technologies d'apprentissage modernes.
 Contributions en tant que RSS
Contributions en tant que RSS
Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !