Federated Learning: The Future of AI Without Compromising Privacy

Federated Learning (FL) has become a paradigm-shifting technology in AI, allowing data scientists to work with private data. In comparison to the standard machine learning approach, where all the individual client data must be collected and moved to a centralized server, with the Federated Learning approach, model training can be done directly on the clients without ever exposing sensitive data.
When we speak about “standard machine learning,” we mean the classical approach where data is collected from all the different client devices and then brought over to a centralized repository where the data is stored. A data scientist then builds, trains, and evaluates their model on this large dataset.
As you may already think, this approach has several drawbacks. The sensitive client data gets exposed several times during the whole end-to-end process. It must be transported over the network, and in addition to that, any data scientist (or, in that regard, any person) with enough privileges on the central repository will be able to see ALL the data from all the clients.
And this is exactly where the federated learning approach comes in. Here, the data doesn’t get collected and moved to a central repository/server. The model information itself gets transported to the client devices directly, and it will be trained there with the available data from the client. This can be significant for any institution that handles sensitive data and is not willing to share that information, such as Electronic Health Records (EHR) from hospitals.
How Federated Learning Works

Figure 1 Federated Learning Training Process (Source: Glanz & Fallen, 2021, The Federated Learning Lifecycle)
The necessary steps for the Federated Learning Training Process can be seen in Figure 1
- Model Broadcast – The latest model and training instructions are downloaded to the clients from the orchestration server. A “model” in this regard can be any Neural Network, Linear Regression model etc.
- Client Training – Clients then train their own models locally with their local data.
- Aggregation – After all clients have trained their local models, the model updates are sent back to the server, where all the updates from the clients are aggregated. The simplest form of aggregation would be to just take the average from all the client updates.
- Model Update – Following the aggregation, the server applies this aggregation to the global model, which is later sent again to the clients for a new training round.
Now to answer the question, what is a “client”? We often talk about cross-device and cross-silo in FL. For the cross-device scenario, a client can be, for example, any mobile device or an Internet of Things (IoT) device like smartwatches. And for the cross-silo scenario, a client can be an entire institution, organization etc. They then have their own servers which hold their data.
Where Federated Learning can be used
Now that we’re familiar with federated learning, let’s explore some real-life case studies. There are potentially endless applications for FL in domains such as Healthcare, Finance, Smartphones, Smart Cities, Recommendation Systems, etc. Let’s focus on two examples for now.
Next Word Prediction in a Mobile Keyboard
Next word predictions aim to improve the user experience during typing. Given a phrase, the model tries to find the best matches for the next word. This can be seen in Figure 2. Given the phrase “I love you” the Google Gboard predicts as next words as “too” then “so much”, and as a third-best option, “and”.

Figure 2 Next word predictions in Gboard. Based on the context “I love you”, the keyboard predicts “and”, “too”, and “so much”. (Source: Hard et al., 2019)
The user’s phone locally stores the information about what he/she has typed into their keyboard and builds its own dataset with this information. Hard et al. (2019) built a model called Coupled Input and Forget Gate (CIFG), which is a variant of a Long Short-Term Memory (LSTM) model for predicting the next words. They trained their model with FL so that each smartphone trained its own local CIFG model, and then all the model updates were aggregated on a local server for several training rounds. Their results showed that the resulting model had performance comparable to a centrally trained one, but without ever sharing client data among each other.
Stroke Prediction with FL
Prevention of strokes and managing associated risk factors have been global public health priorities. In their work, Ju et al. (2020) proposed a framework to predict the risk of stroke and deploy their federated prediction model on cloud servers. They collaborated with 5 Chinese hospitals to validate their approach. Several medical and technical experts preprocessed raw medical data available at the hospitals into Out- and In-patient EHR and Out- and In-patient Prescription datasets. From there, they hand-selected several features related to stroke and finally fed those features into a neural network that predicted the probability of a stroke. They trained their model with FL and used the weighted average as an aggregation algorithm. Their approach can be seen in Figures 3 and 4. Figure 3 also shows the implementation of a WeChat mini-application, in which experts can oversee the training processes. Their results again showed performance comparable to a centrally trained model.
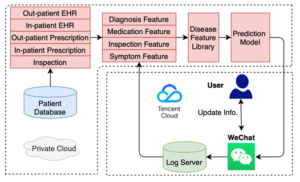
Figure 3 Workflow of the Stroke Prediction Model (Source: Ju et al. 2020)
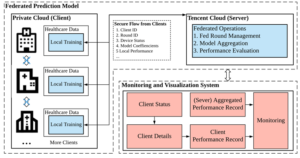
Abb4 Federated
Figure 4 Illustration of Architecture of Federated Prediction Model (Source: Ju et al., 2020)
How can you implement our own FL models?
There are already many tools and frameworks available for FL.
If you’re familiar with Google’s TensorFlow, you can get started with TensorFlow Federated (https://www.tensorflow.org/federated). However, it only provides a simulation environment in which you can test your assumptions and do some Proof of Concepts. As of the time of writing, it’s not meant for production use.
If you want something that is already widely used (mainly in the Chinese market) you could try FATE (https://fate.fedai.org). It supports both TensorFlow and PyTorch, both simulation mode and production environments, and can be used for both cross-device and cross-silo scenarios.
But there are many more tools and frameworks in development. Some of them listed here:
- PySyft (https://com/OpenMined/PySyft)
- IBM Federated Learning (https://com/IBM/federated-learning-lib)
- Flower (https://github.com/adap/flower)
- OpenFL (https://github.com/securefederatedai/openfl)
- FedML (https://doc.fedml.ai)
Conclusion
In conclusion, FL can be greatly beneficial where data is sparsely available, and privacy is a concern. The novel technology has already been proven to be useful and shows great performance in real-world applications. Many FL tools and frameworks are in active development, which shows that FL receives a lot of attention from many big players.
References
- Glanz, E., & Fallen, N. (2021). What Is Federated Learning? (1st edition) [OCLC: 1281679172]. O’Reilly Media, Inc.
- Hard, A., Rao, K., Mathews, R., Ramaswamy, S., Beaufays, F., Augenstein, S., Eichner, H., Kiddon, C., & Ramage, D. (2019, February 28). Federated learning for mobile keyboard prediction. Retrieved December 16, 2023, from http://arxiv.org/abs/1811.03604
- Ju, C., Zhao, R., Sun, J., Wei, X., Zhao, B., Liu, Y., Li, H., Chen, T., Zhang, X., Gao, D., Tan, B., Yu, H., He, C., & Jin, Y. (2020, December 14). Privacy-preserving technology to help millions of people: Federated prediction model for stroke prevention. Retrieved December 16, 2023, from http://arxiv.org/abs/2006.10517

![]() Cedric Aebi is Part-time Student MSE with specialization in Data Science at BFH School of Engineering and Computer Science.
Cedric Aebi is Part-time Student MSE with specialization in Data Science at BFH School of Engineering and Computer Science.
![]() Souhir Ben Souissi
Souhir Ben Souissi
Dr Souhir Ben Souissi is a Tenure Track Professor of Data Engineering at the Institute for Data Applications and Security (IDAS) at the Bern University of Applied Sciences. Her research focuses, among other things, on the topicsof Medical Decision Systems, Semantic Web Technologies and Multi Criteria Decision System.
 Contributions as RSS
Contributions as RSS
Leave a Reply
Want to join the discussion?Feel free to contribute!