Leonardo da Vinci war transdisziplinär und seiner Zeit voraus. Bis heute ist das Universalgenie immer wieder Vorbild. Unser Autor beschreibt gelungene Anwendungen aus offenen Daten aus Kultur- und Gedächtnisinstitutionen, die seinen Geist atmen und am Kulturhackathon «Coding da Vinci» entstanden sind.
Der Rennaissance-Maler ist nicht nur der Schöpfer der Mona Lisa mit ihrem rätselhaften Lächeln. Zeit seines Lebens (1452–1519) widmete sich Leonardo da Vinci neben der Malerei mathematischen, physikalischen und anatomischen Forschungen, er erfand Fluggeräte und experimentierte mit der Energiegewinnung aus Sonnenlicht. Seine Notizbücher, Zeichnungen und Skizzen umfassen mehr als 6.000 Blätter voller Beobachtungen, Entwürfe und Illustrationen zu Biologie, Kosmologie, Architektur und Technik.
Auch 500 Jahre später steckt an der Schnittstelle von Kunst und Tüftelei viel Potenzial. Insbesondere offene Kulturdaten bieten vielfältige Möglichkeiten für eine kreative Auseinandersetzung mit dem kulturellen Erbe – von spielerischen bis erkenntnisgenerierenden Ansätzen. Diesem Thema hat sich der nach dem Renaissance-Künstler und Universalgelehrten benannte Kultur-Hackathon Coding da Vinci verschrieben. Kultur- und Gedächtnisinstitutionen stellen das Material: Datensätze wie digitalisierte Gemälde, Fotos, Audiodateien oder 3D-Objekte einschließlich ihrer Metadaten in offenen Formaten und unter offenen Lizenzen. Erst diese Offenheit eröffnet die Möglichkeit einer weitreichenden Nachnutzbarkeit. Dann sind EntwicklerInnen, DesignerInnen, KünstlerInnen, GamerInnen und Kultur(-daten)begeisterte eingeladen, in interdisziplinären Teams Prototypen für Anwendungen wie mobile Websites, Apps, interaktive Spiele und mehr zu entwickeln. Die besten Ideen werden jeweils ausgezeichnet, wie im Video vom Anlass zu sehen ist.
Coding da Vinci zeichnet sich durch sein spezifisches Format aus: Während die meisten anderen Hackathons im Stile eines „Marathons“ meist an einem Tag oder Wochenende durchgeführt werden, erstrecken sich die von regionalen Veranstalterteams ausgerichteten Hackathons von Coding da Vinci über eine Zeitspanne von sechs bis zehn Wochen. Erst so wird es möglich, dass sich die oft getrennten Welten kreativer Technologieentwicklung und institutioneller Kulturbewahrung treffen können, um in einen Austausch zu treten und voneinander zu lernen. Über 100 Kultur- und Gedächtnisinstitutionen aus Deutschland und teilweise Europa haben bislang als Datengeber teilgenommen. Es wurden ebenso viele Projekte entwickelt, deren Vielfalt hier nur durch ein paar Beispiele aus dem Kreis der Gewinner der letzten Jahre illustriert werden soll.
Die App Zeitblick beruht darauf, dass ein Selfie in Sekundenschnelle durch ein im Gesichtsausdruck möglichst ähnliches historisches Bild ersetzt wird. Hierfür greift eine Gesichtserkennungssoftware auf eine Datenbank mit über 1.300 Gesichtern aus dem offenen Bildarchiv des Museums für Kunst und Gewerbe Hamburg zu. Selbstverständlich lassen sich diese DoppelgängerInnen aus der Kunst dann über Social Media auch mit anderen teilen.
Das Projekt Berliner MauAR macht das Smartphone zur Zeitmaschine, indem es die Berliner Mauer mittels Augmented Reality und GPS-Lokalisierung in historischen Bildern wieder an den Originalorten erscheinen lässt. Zu den Fotos der Stiftung Berliner Mauer lassen sich Texte öffnen, die tiefere Einblicke in die Geschichte Berlins geben.
Das Virtual-Reality-Projekt Skelex nutzt 3D-Scans von biologischen Sammlungsobjekten des Museums für Naturkunde Berlin und präsentiert sie in einem virtuellen Museumsraum. Dort kann man an einem Schlangenkopf all das ausprobieren, was im Museum sonst streng verboten ist: anfassen, drehen, in einem Explosions-Diagramm auseinander nehmen, vermessen und anderes mehr.
JibJib ist eine App, die Vogelstimmen erkennt. Mit Machine Learning und einem Trainingsdatensatz bestehend aus mehr als 80.000 Audioaufnahmen aus dem Tierstimmenarchiv des Museums für Naturkunde Berlin ist die App in der Lage, etwa 200 verschiedene Vögel zu unterscheiden.
Antlitz Ninja ist eine spielerische Webanwendung, die es ermöglicht, Gesichtspartien aus Werken der Kunstgeschichte aus der Sammlung des Städel Museums in Collagen neu zu kombinieren. Der kreative Prozess der Rekombination dreier zufällig ausgewählter Bildausschnitte lenkt den Blick auf die Details der historischen Kunstwerke. Die eigenen Kompositionen lassen sich dann auch herunterladen.
Alle diese Projekte stehen ebenso wie die darin genutzten Daten unter offenen Lizenzen und können daher frei genutzt und weiterentwickelt werden. Lust bekommen? Eine Übersicht der Projekte und der verwendeten Daten sind im Projektportal zu finden.
https://www.societybyte.swiss/wp-content/uploads/2019/02/iStock-456054995.jpg14142121Dominik Schollhttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpDominik Scholl2019-02-05 12:33:432019-03-04 13:59:50Wenn da Vinci Pate steht für einen Kulturhackathon
Der Verein opendata.ch hat gestern Abend einen neuen Präsidenten gewählt. Andreas Kellerhals, der frühere Direktor des Bundesarchivs übernimmt das Amt des scheidenden André Golliez. Ein Gespräch über die neue Strategie des Vereins.
Herr Kellerhals, Sie waren bis Januar dieses Jahres Direktor des Bundesarchivs, noch bis Ende Jahr sind Sie Beauftragter des Bundes für OGD und nun wurden Sie zum Präsidenten von opendata.ch gewählt– was ist Ihre Motivation?
Andreas Kellerhals
Andreas Kellerhals: Mit dem Abschluss der Redaktion der neuen Strategie ist auch meine Arbeit als Beauftragter für OGD abgeschlossen. Ich werde ab Jahresbeginn im Ruhestand sein und kann mich voll und ganz opendata.ch widmen, ohne dass mein Amt in Konflikt geraten könnte mit weiteren beruflichen Verpflichtungen. Das Thema Open Data beschäftigt mich schon seit der ersten Open Data Konferenz in der Schweiz 2011 im Schweizerischen Bundesarchiv. Ich war massgeblich verantwortlich für die Realisierung des ersten gesamtschweizerischen Portals opendata.admin.ch (2013) bzw. von dessen Nachfolgeportal opendata.swiss (2016).
Bei diesen Projekten bemühte ich mich vor allem auch darum, möglichst viele Daten zu publizieren und auf dem Portal zu referenzieren sowie die Nutzung dieser Daten anzuregen. Zu einer wirksamen Förderung einer Open Data-Kultur, wie das schon in der ersten bundesrätlichen Strategie geheissen hat, fehlten damals leider die nötigen Mittel. Aber die Plattform und die bis heute publizierten Datensätze sind dennoch ein ziemlicher Erfolg. Es ist jedoch auch klar, dass sowohl publikationsseitig wie nutzungsseitig noch vieles zu tun bleibt. Da will opendata.ch unterstützen und anregen. Die weitere Entwicklung sollte nicht einfach angebotsseitig, sondern im Dialog mit allen Stakeholdern definiert werden. Da gibt es also viele Betätigungsfelder, die ein Engagement lohnen.
Wie profitieren Sie von Ihren vorherigen Ämtern, und wie sieht Ihr Ideal aus?
Die Erfahrungen aus der Verwaltung, aus dem Prozess der Strategiedefinition ebenso wie aus der konkreten Arbeit der Strategieumsetzung halte ich für eine gute Voraussetzung, um das bisher schon erfolgreiche Werk von opendata.ch weiterzuführen. Das Ideal ist immer noch eine transparentere Welt mit klar wahrgenommenen Verantwortlichkeiten und folglich auch einer selbstverständlichen Rechenschaftsbereitschaft, in der Lösungen partizipativ entwickelt und Ideen im Dialog umgesetzt werden.
Was wollen Sie als Präsident mit dem Verein erreichen – Stichwort neue Strategie?
Die neue Strategie von opendata.ch – ebenso wie die neue Strategie des Bundesrates – orientiert sich eigentlich immer noch an den gleichen „grossen“ Zielen: mehr Transparenz, mehr Partizipation, bessere Rechenschaftsfähigkeit – der allgemeine Kontext der Open Data Bewegung bleibt auch weiterhin der massgebliche Bezugsrahmen. Für die Umsetzung muss alles konkreter und damit automatisch auch bescheidener formuliert werden, aber die Ambitionen bleiben: Es ist klar mein Ziel, mit opendata.ch dazu beizutragen, dass mehr Daten publiziert werden. Alle neuen Daten sollten automatisch als offene Daten genutzt werden können und auch die bereits bestehenden sollten, wenn möglich thematisch aufeinander abgestimmt und nachfrageorientiert, offen publiziert werden.
Generell geht es mir darum, dass dank offener Verwaltungsdaten nicht nur an Abstimmungssonntagen Demokratie praktiziert wird, sondern bereits viel früher in Verwaltungsprozessen eine breite Partizipation der Betroffenen und Beteiligten möglich wird.
Die publizierten Daten sollen ausreichend beschrieben sein und in nutzbaren Formaten vorliegen, d.h. vorzugsweise als Linked Open Data. Daneben gibt es natürlich noch die Fragen der rechtlichen und finanziell unentgeltlichen Zugänglichkeit. Zu deren Lösung kann opendata.ch einiges beitragen. Weiterer Schwerpunkt muss zudem die Förderung der so genannten Digital Skills und der Data Literacy sein, ohne die ein kompetenter Umgang mit Daten nicht möglich ist. Auch dazu hat opendata.ch schon viel geleistet und wird dies auch künftig tun.
Ein Blick in die Zukunft: die Schweiz in 10 Jahren im Bereich Open Data und OpenGLAM – Ihre Vision?
In zehn Jahren werden alle Verwaltungsdaten von Bund, Kantonen und Gemeinden als offene Verwaltungsdaten publiziert und die schon bestehenden Datenbestände, an denen sich ein öffentliches Interesse manifestiert hat, sind ebenfalls frei zugänglich. Daten als Infrastruktur werden weltweit Realität sein und die Schweiz wird eine gute Position in diesem Daten-Ökosystem einnehmen. Daten aus dem GLAM-Bereich müssen unbedingt dazu gehören. Alle diese Daten werden rege genutzt, sowohl in demokratischer Absicht, zu Bildungszwecken oder auch mit wirtschaftlichen Zielsetzungen.
Wenn Sie speziell den GLAM-Bereich ansprechen, dann sind viele Nutzungsmöglichkeiten denkbar, aktuell in politischer Perspektive z.B. speziell auch für die Provenienzforschung resp. den transparenten Provenienznachweis.
Generell geht es mir darum, dass dank offener Verwaltungsdaten nicht nur an Abstimmungssonntagen Demokratie praktiziert wird, sondern bereits viel früher in Verwaltungsprozessen eine breite Partizipation der Betroffenen und Beteiligten möglich wird. Ausserdem werden in zehn Jahren neue wirtschaftliche Aktivitäten Alltag geworden sein, die auch auf diesen Daten basieren und – vielleicht – werden sogar die Unternehmen gemerkt haben, dass die Publikation ihrer Daten nicht das Ende erfolgreicher Geschäftsführung bedeutet, sondern ein wichtiger Faktor für wirtschaftlichen Erfolg ist.
https://www.societybyte.swiss/wp-content/uploads/2018/11/DSCF0966_bearb-scaled.jpg12801920Anne-Careen Stoltzehttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpAnne-Careen Stoltze2018-11-28 15:36:002018-11-29 17:06:46«Daten als Infrastruktur werden Realität sein»
Ähnliche Beiträge
Es wurden leider keine ähnlichen Beiträge gefunden.
On 29 October 2018, Wikidata turned six. What was at its launch a fledgling project is today inspiring numerous people with new and surprising ideas about what could be achieved in a linked data world. In this article we will give a brief overview of how Wikidata is used in the heritage sector and how the community is doing in addressing the egg-and-hen-problem of linked open data.
Over the past years, a growing community has formed on Wikidata around heritage data. Its members are ingesting, cleansing and improving data; discussing data modelling issues; contacting new data providers and developing applications based on Wikidata. Their vision is for Wikidata to become a central hub for data integration, data enhancement and data management in the cultural heritage domain. According to the group’s mission statement, this includes:
“establishing Wikidata as a database that covers the entire world’s cultural heritage;
establishing Wikidata as a central hub that interlinks [heritage] collections around the world and provides links to bibliographic, genealogical, scientific and other collections of information and thereby functions as the ultimate authority file providing mapping information between these different collections;
fostering truly multilingual and global collaboration around the description and management of heritage data among people from various backgrounds;
leveraging synergies between institutions, helping them to reduce duplicate work;
encouraging debate in the community by highlighting and interrogating differences in perspective; and
providing a single source of data for some of the most popular web sites and apps, including Wikipedia infoboxes and lists” (Wikiproject Cultural heritage).”
As the last point makes it clear, the actual usefulness of the data comes with its use. Either in the form of services that are targeted at end users or by providing insights that are turned into stories that can be shared. To create a flourishing ecosystem of Wikidata-based applications running on high-quality data, a critical chicken-or-egg problem needs to be overcome: without complete and high-quality data, there are no cool apps. But without interesting apps, there are few incentives to provide data and to improve its quality. In other words: the main drivers of data quality and completeness are interesting and widely used applications, while the motivation to develop good apps is far greater if they can build upon a high-quality and complete data bases. In this article we will present a few of the things the Wikidata community is doing to address its chicken-or-egg problem.
Data Use in Wikipedia and other Wikimedia Projects
One of the basic ideas behind Wikidata was to create a central repository of structured data for Wikimedia projects, such as the free online-encyclopedia Wikipedia, Wikimedia Commons, and others. The immediate use of Wikidata in the context of Wikipedia can take the form of infoboxes or lists. An example of a Wikidata-powered infobox can be found in the Wikipedia article on Ferdinand de Saussure; it features an image and structured data that are partly pulled from Wikidata. An example of a Wikidata-powered list can be found in the Portuguese article about paintings by Alfredo Norfini.
Such infoboxes and lists are an immensely useful tool to eliminate the duplication of efforts across Wikipedia’s different language communities, as the data can be curated in a central database. At the same time, they have a large impact in terms of visibility of the data thanks to the prominence of Wikipedia on the Internet. Yet, some of the largest communities, such as the German or the English Wikipedia communities, which could generate substantial spill-overs into smaller language communities, have so far shown the biggest restraint when it comes to taking up Wikidata-powered infoboxes and lists on a broader scale. The arguments brought forward have mostly been related to data quality or to the fear of an exacerbation of the vandalism problem. Vandalism could indeed be encouraged by the high visibility of the centrally managed data and it might be difficult to counteract data manipulations. Many communities have indeed long questioned the adequacy of Wikidata’s edit tracking tools, which has triggered the improvement of these tools over the years. Some members of non-English communities may in addition feel uneasy about having to curate data on the Wikidata platform, which involves taking part in community discussions that predominantly take place in English. Furthermore, larger communities may expect fewer benefits from Wikidata than smaller communities, as they have already quite good data coverage in many areas thanks to established methods of data curation that were developed prior to the introduction of Wikidata.
On the other end of the spectrum, some of the smaller (or medium-sized) language communities, such as the Catalan Wikipedia, have been pioneers in this area, creating infobox templates with interactive maps, detailed career information for biographies and various other information directly fetched from Wikidata. In fact, in fall 2017 the Catalan community announced that over 50% of the 550’000 articles on Catalan Wikipedia were using data from Wikidata.
In addition to the direct inclusion of data from Wikidata in Wikipedia articles, Wikidata has also been used as a basis for the automatic generation of article stubs that could then be extended by Wikipedia editors. This approach is especially useful for harmonizing the structure of articles in specific areas. One of the tools for this is the “Mbabel Article Generator”, which was first developed for a New-York-based project, about museums, and was then extended by a Brazilian team to other classes of subjects, such as works of art, books, films, earthquakes, and journals. Here again, a Wikidata-based tool can help reduce the workload of Wikipedians by using centrally curated data that can be applied across language communities. Another tool that serves a similar purpose for biographical articles is “PrepBio”.
Data Use Beyond the Wiki-World
The use of Wikidata is not confined to Wikimedia projects alone. Here are few examples of uses of Wikidata outside the realm of the Wiki-world:
Points of interest. One prominent application is “Monumental”, a Wikidata-based web app which displays information related to historical monuments on a map. The app allows logged-in users to directly edit Wikidata and includes a Wikidata game for the matching of Wikidata entries with Wikimedia Commons categories. The app is used as part of “Wiki Loves Monuments” – the world’s largest photo competition. This contest has been accompanied by an effort to gather monument-related data in a centralized database which pre-dates Wikidata. This explains why the app has been able to provide good coverage of historical monuments for numerous countries. Monuments data is also used by “Panandâ”, a mobile app for the exploration of the cultural heritage of the Philippines based on the historical markers and commemorative plaques installed by the National Historical Commission. These types of apps could in the future be adapted to other areas where objects of interest are displayed on a map, e.g. museums, water-fountains, public artworks, cultural venues, etc.
Visual art. Another app that has been around for a while is “Crotos”. It builds upon the “Sum of All Paintings Project”, the first Wikidata project to clearly announce the goal of gathering data about all the cultural heritage of a specific kind. It provides a search and display engine for visual artworks, based on Wikidata and using Wikimedia Commons files. Search results can be filtered using work categories and time periods. Artworks can be displayed in random or chronological order. Like in Monumental, there is a contribution mode, which allows works with missing properties to be filtered, so that the information can be completed by the user.
Bibliographic data. Yet another area of cultural heritage is covered by “Scholia”, a web app that presents bibliographic information and scholarly profiles of authors and institutions using Wikidata. It is being developed in the framework of the larger WikiCite initiative, which seeks to index bibliographic metadata in Wikidata about resources that can be used to substantiate claims made on Wikidata, Wikipedia or elsewhere. While its intended scope is equally comprehensive as for the two previous examples, work is still at an early stage and Scholia is therefore biased due to its fragmentary data basis.
Thematic timelines. The most well-known application here is “Histropedia”, which uses data from Wikipedia and Wikidata to automatically generate interactive timelines with events linked to Wikipedia articles. Users can combine timelines and events to create their own custom timelines. The web app “Tempo-spatial display” adds another dimension by combining chronological and geographic information on a specific topic, including a timeline of events and a map.
New forms of access to heritage collections. Several applications help us explore heritage collections, such as “Collection Explorer” which focuses on a specific institution, “Manuscript Explorer” and “Astrolabe Explorer”, which focus on specific thematic areas or an app exploring the Sibthorp & Bauer Expedition and subsequent book: the Flora Greaca, a book full of beautiful illustrations which can be viewed via the app. Further applications provide new ways of access heritage collections: “Textes d’affiches” is a web app that links movie posters with the artistic works they are based on. It points users who are more familiar with the movies to the library content in the form of full-texts on the online platform of the National Library of France, and so giving film buffs more material for dinner party conversations! “Cultural History Baseball Cards” in turn allows users to navigate through both scholarly and cultural materials related to the players, managers, and executives who have shaped the game’s history. The number of other areas these applications could be adapted to is almost limitless.
Networks of people. The application “Ancient intellectual network” provides a visualization of the relationships between master and student from Socrates to the end of the Hellenistic period. There are also a few tools that can be used to visualize family trees and relationships, such as the “Ancestors Tool” and “GeneaWiki”. A network visualization feature has also been implemented on “Scholia”, covering current academic networks. Similar applications could be imagined for other types of relationships between people.
Collaborative cataloguing. A particularly interesting application is “Inventaire”, which caters to its own community of users who provide information about the books in their private collections, including the information under which conditions the books can be borrowed. This service is based on Wikidata and provides an excellent example how to exploit the symbiosis between a smaller community and Wikidata at large. The users of Inventaire are contributing to an ever-growing catalogue of books that is automatically integrated with the data from library catalogues that are amassed in Wikidata.
Wikidata as an authority file. As “Text razor“ demonstrates, Wikidata’s knowledge graph can be used for entity extraction (named entity recognition) and content categorization. In fact, Wikidata is playing more and more the role of an authority file by complementing long-established authority files from the heritage field, such as VIAF or GND, which are instrumental in disambiguating and interlinking entries in library catalogues and archival finding aids.
Concluding Remarks
As this article has shown, there is already a variety of Wikidata showcase applications in the field of cultural heritage, and activities to resolve Wikidata’s chicken-or-egg problem are well under way. As the examples also demonstrate, more efforts are needed to improve data quality and completeness. Most promising from this point of view are applications that are linked to campaigns to improve the underlying data, such as Monumental, or applications that encourage data provision and enhancement by community members, such as Inventaire or the use of Wikidata in Wikipedia. We can only hope that a positive feedback loop ensues from these first Wikidata-based applications, and that we will see many more and better apps in the future, along with concerted efforts to enhance the quality and completeness of the data – the prerequisites of exciting applications!
References
“Wikidata, a rapidly growing global hub, turns five” (blog post by Andrew Lih and Robert Fernandez, 30 October 2017).
https://www.societybyte.swiss/wp-content/uploads/2018/11/Crotos.png8061347Beat Estermannhttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpBeat Estermann2018-11-07 10:32:582019-09-26 13:04:19How Wikidata Is Solving Its Chicken-or-Egg-Problem in the Field of Cultural Heritage
In this article we provide some insights and lessons learned acquired with the realization and the maintenance of the Linked Data Service of the Federal Spatial Data Infrastructure (FSDI) geo.admin.ch. We also try to identify pitfalls and areas where engagement and investments are needed in order to facilitate unlocking the potential of the Geographic Information and bringing it on the Web.
Geographic Information and the Web
The Geographic Information (GI) and the Web appear to be good friends: GI is pervasive on the Web and Web technologies are used by the GI community to provide access to geodata. In August 1991 Tim Berners-Lee announced the WWW Project on the newsgroup alt-hypertext; the Xeroc Parc Map Viewer was one of the first Web applications and went online in 1993. Since then the GI community has evolved around the concept of spatial data infrastructures (SDIs) with the main idea to use the Web in order to connect isolated GI Systems and exchange GI. The implementation of SDIs has been supported by an international, top down and highly centralized standardization effort driven by organizations like the Open Geospatial Consortium (OGC) and ISO Technical Committee 211.
The Web has instead moved with a complete different approach, more agile, decentralized and bottom up. Just consider, for example, that the GeoJSON (a geospatial data interchange format based on JSON) and the JSON-Schema (the vocabulary to annotate JSON documents) specifications sum up to some fifty pages, while the OGC standard GML (an xml-based modeling language and interchange format) is about four hundred pages.
At the end of the story, the Web is today mostly agnostic about SDIs. The discovery of information resources in SDIs is delegated to catalog services providing access to metadata and users generally cannot simply follow links to access data. OGC Web services do not address indexing of the resources by general purposes search engines.
To address this and other related issues, OCG and the W3C have teamed up to advise on best practices for the publication of spatial data on the Web based on Linked Data.
The Linked Data Service of geo.admin.ch
With these considerations in mind, we at swisstopo started to consider the possibility to publish geodata as Linked Data in 2016. We launched a project with the objective to publish a selection of geodata: the result is the Linked Data Service of geo.admin.ch, the Federal Geoportal. The service is operational since March 2017 and we publish so far two main datasets: swissBOUNDARIES3D (administrative units versioned since 2016) of swisstopo and the Public Transport Stops of the Federal Office of Transport.
We use a standard process for the publication of data according to the Linked Data principles, implying the serialization of the data in RDF (here we use the GeoSPARQL standard), the storage of the triples in a triple store and the setup of a Linked Data Frontend.
We use the Virtuoso Open Source Edition as triple store and the open source product Trifid as Linked Data frontend for URI dereferencing and content negotiation.
Both software components are dockerized: we use Rancher as composer.
The good
Providing geodata as Linked Data results in a mutual exchange of benefits between the GI community and the Linked Data / Web community. The GI community brings new ways of querying data: the GeoSPARQL standard is in fact not just a vocabulary for encoding geodata in RDF, since it provides above all extensions to the SPARQL language, enabling to query resources based on their spatial relations. Queries like “Find all resources of type A (with a point geometry) within the resource of type B (with a polygon geometry)” or “Find all resources of type A within a distance of X kilometers from point C” are simply not possible with standard SPARQL.
On the other hand the Linked Data / RDF approach to data modeling can ease the burden of communicating data semantics. Data modeling within the GI domain is based on the “model driven approach”, where data semantics resides in (complex) conceptual and database schemas and has been traditionally very hard to share.
Linked Data users do not need to understand / know all this complexity to adequately use the data, since data semantics is in the data itself. Here not only objects (resources) are on the Web but also objects properties (what we call attributes in the GI domain and predicates in RDF) are first class objects and are on the Web: objects types and predicates are described via web-accessible open agile vocabulary definitions and this definitions are reusable.
The bad
The bad news is that Virtuoso Open Source does so far not support GeoSPARQL (there are plans to support it according to this tweet). It actually supports spatial queries but these are based on built-in spatial functions instead of using those defined by the GeoSPARQL standard. Within the open source community we don’t see so far a valuable alternative to Virtuoso, on the other hand the interest about GeoSPARQL is growing more and more and commercial solutions exist, that start to support it. GraphDB for example has a good support and so should the new Stardog version (to be tested).
We argue that the standard approach to Linked Data publication built around a triple store is not very adequate when:
A data publication pipeline is already in place, as is the case for the FSDI. Here one has to deal with data redundancy and synchronicity;
Data to be published is somehow massive and dynamic, meaning there is a high update frequency (daily, hourly).
To address these issues we are investigating alternative solutions based on virtual graphs. The idea here is to have a proxy on top of the main data storage and let the proxy provide RDF serialization at runtime.
Again the problem is that open source solutions are very few: D2RQ, a reference system for accessing relational databases as virtual RDF graphs, is a very old technology and does not seem adequate for a production environment; ontop seems a promising technology but does not support so far GeoSPARQL (there are plans to support it according to this post).
One more issue about usage: we are monitoring the service and the statistics do not show so far big numbers. We will have to work in this sense maybe by supporting showcases and make developers aware of the power of the Linked Data approach: one simple data model (RDF) with enough semantics enabling easy understanding of the data and a unique interface (SPARQL).
The ugly
When we started our project, one of the objectives was to try to improve the indexing of our data by the main search engines: Linked Data is an easy and valuable way to bring geodata to the Web and to improve geodata visibility and cross-domain interoperability.
We were aware that we had to work with the schema.org vocabulary and we spent some time in trying to debug our RDF serialization with the Google structure data tools. We eventually had to realize that Google does not really follow the “open world assumption” to Linked Data publication: the structured data tool have an issue with mixed vocabularies, simply said they only recognize schema.org definitions, while definitions from other vocabularies produce errors.
Now schema.org is simply not sufficient to describe geodata. Let us make a simple example: to tag a resource of type “administrative units” one can use the schema.org type “AdministrativeArea” but there is no possibility to specify the level of the administrative unit (is it a Municipality or a Canton?). Schema.org fails on one of the main Linked Data principles: reuse. It just does not care about existing standards and vocabularies.
Google has recently launched a new “Dataset Search” service with a bit more “openness”, since here they also support the “Data Catalog Vocabulary” (DCAT) from the W3C beside schema.org.
Amazon has also recently launched its “Registry of Open Data on AWS” for discovery and sharing of datasets available as AWS resources.
The Frictionless Data initiative from Open Knowledge International is yet a further approach to data publication and sharing.
In the quest for unlocking the potential of (geo)data, data providers have to navigate on sight in a sea full of alternative and competing «same-but-different» solutions.
We argue that the Linked Data approach is the one with the higher, yet unexplored potential.
https://www.societybyte.swiss/wp-content/uploads/2018/10/Beitragsbild_Swiss_Boundaries.jpg4751141Pasquale Di Donatohttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpPasquale Di Donato2018-10-27 12:05:382018-10-26 12:06:56The Linked Data Service of the Federal Spatial Data Infrastructure
“S-O-WAS” – Semantic-and -Ontology-based-Web-Applications-Searchform” erlaubt die maschinengestützte Formulierung von semantischen Suchanfragen in normierten Metadatenfeldern, gezeigt am Beispiel einer Autoren- und Schlagwortsuche mittels Identifikator der Gemeinsamen Normdatei. Unsere AutorInnen haben eine Konzeptstudie während des OpenGLAM.at Kulturhackathons 2018 erarbeitet.
Die zahlreichen und vielfältigen Bestände von Galleries, Libraries, Archives and Museums (GLAM) sind im Laufe von Jahrhunderten entstanden. Die umfangreichen Sammlungen stellen KuratorInnen vor die Aufgabe, geeignete Ordnungsprinzipien zu etablieren und effiziente Suchmöglichkeiten anzubieten. Eine besondere Herausforderung stellen Rechercheanfragen dar, die selbst Ungenauigkeiten bergen oder mit Unbekannten operieren. Dem klassischen enzyklopädischen Weg einer Vorrecherche kann mittels semantischer Suchabfragen aus Linked-Open-Data-Quellen eine moderne Alternative entgegengestellt werden. In Verbindung mit dem in GLAM-Institutionen verbreiteten Einsatz von Normdaten1 zur Beschreibung von geistigen Schöpfern, mitwirkenden Personen und unterschiedlichen Schlagworten können solche Suchabfragen abseits einer potentiell unscharfen Textsuche auch durch den Einsatz von Normdaten-Identifikatoren eine hohe Trefferpräzision erreichen.
Unscharfe Suche in scharfen Metadaten
Die Beschreibung von Bestandsobjekten in GLAM-Institutionen hat eine lange Tradition und baut auf allgemein verbreiteten Regelwerken und Standards auf.2 Diese Metadaten bilden dann bereits einen Textkörper, der dann auch mit Volltextelementen wie Beschreibungen, Abstracts ergänzt werden kann. Die Indexierung der verfügbaren Textbausteine erlaubt eine Textsuche. Die grösste Herausforderung dabei ist die Genauigkeit, die mit Hilfe von Methoden der Informationswissenschaft gemessen wird. Eine der häufig verwendeten Methoden ist, mit dem sogenannten F-Mass sowohl Genauigkeit (precision) als auch Trefferquote (recall) gewichtet zu ermitteln, so dass die Ergebnisliste möglichst wenige unerwünschte Objekte enthält (“false positives”) und andererseits möglichst wenige gewünschte Objekte ausgelassen werden (“false negatives”).
Die Verschlagwortung im speziellen und die Nutzung von Normdaten auch im Bereich formaler Beschreibungen, wie bei den an einem Bestandsobjekt beteiligten Personen, dient nun dem Zweck, diese Genauigkeit bei der Suche zu verbessern. Statt einer rein technischen Extraktion von Wörtern werden diese im inhaltlichen Bereich intellektuell zugewiesen. Das Wort “Logikkalkül” ist dann nicht einfach nur ein Wort, das zufällig im Text auftaucht, sondern es beschreibt einen wissenschaftlichen Themenbereich, der dem Bestandsobjekt (hier beispielsweise ein Buch über Logik) bewusst zugeordnet wird. Ist der Suchbegriff Teil der Schlagwortliste, so liegt es nahe, die Relevanz gegenüber den Objekten, die den Begriff nur beinhalten, höher einzustufen. In formalen Fragen helfen Normdateien bei der Suche nach Personen, diese eindeutig, trotz häufig vorkommender vollständig identer Namen zu unterscheiden und die Genauigkeit der Recherche zu erhöhen.
Das Semantic Web hilft
In vielen GLAMs wird die manuelle Verschlagwortung durch eine wachsende Anzahl von Einzelobjekten zunehmend schwieriger. In den Bibliotheken betrifft dies vor allem die neuen Netzpublikationen3 , die aus diesem Grund zunehmend mit maschineller Unterstützungen verschlagwortet werden (Faden und Gross 2010; Hinrichs et al. 2016). Eine der grössten Herausforderungen der automatisierten Verschlagwortung ist dabei, eine mit der manuellen Verschlagwortung vergleichbare Qualität zu erreichen.
Das Ziel der hier vorgestellten Überlegungen ist es, die manuell vergebenen, aber normierten Metadaten für eine präzise Suche in den Beständen der GLAMs zu nutzen. Mit Hilfe von Semantic Web Suchtechnologien und auf der Basis der in der Linked-Open-Data-Cloud verfügbaren Daten wird zunächst eine Suche nach Personen durchgeführt, die anschliessend mit einer Suche im Bestandskatalog nach Einzelobjekten auf der Basis manuell vergebener Schlagworte verknüpft wird. Bibliotheken, Sammlungen, Archive und Museen können auf diese Weise das Potential ihrer Metadaten, wie beispielsweise der manuell und aufwändig vergebenen Schlagworte, besser nutzen und mit Hilfe des Werkzeugs “S-O-WAS” ihrem Publikum eine semantische Suche ermöglichen.
Zur Ermöglichung einer semantischen Suche soll zunächst der Informationsreichtum der Linked Open Data Cloud genutzt werden. Insbesondere steht dabei die freie Wissensdatenbank Wikidata4 im Vordergrund, die eine umfangreiche Sammlung von Objekten beinhaltet, die das Wissen in Form von Aussagen und Fakten über diese Objekte strukturiert. Um die Nutzung der Wissensdatenbank zu ermöglichen, stellt Wikidata unter anderem eine Schnittstelle für die Abfrage der Daten mit der Abfragesprache SPARQL5 bereit.
Die Funktionsweise der Abfrage wird im Folgenden anhand eines konkreten Beispiels erläutert.
Semantische Suche nach Personen
Nehmen wir zum Beispiel an, es wird nach einer Person gesucht, die bestimmte Kriterien erfüllen soll. Der Name der Person sei zunächst nicht bekannt. Zum Einen wissen wir, dass die Person ein Autor (männlich) ist, was jedoch zunächst keine Rolle spielt. Wir wissen, dass diese Person im 19. Jahrhundert geboren wurde, in Grossbritannien lebte und von Beruf Mathematiker war. Das Venn-Diagramm in Abbildung 1 veranschaulicht die Einschränkung auf eine diesen Kriterien entsprechende Schnittmenge.
Abbildung 1: Person, lebte in Grossbritannien, geboren im 19. Jahrhundert, Mathematiker.
Allein mit Hilfe dieser Kriterien lässt sich eine semantische Abfrage formulieren, die als Ergebnis eine Liste der Personen zurückliefert, die den Kriterien entsprechen:
SELECT DISTINCT ?Person ?PersonLabel ?GND WHERE {
SERVICE wikibase:label { bd:serviceParam wikibase:language «(AUTO_LANGUAGE),en». }
Betrachten wir zum Beispiel einen Teil der Abfrage, der die Abfragekriterien enthält: ?Person wdt:P27 wd:Q145.
Es wird ersichtlich, dass nicht die Bezeichner selbst, sondern Identifier für Objekte (beginnend mit “Q”) und Prädikate (beginnend mit „P“) verwendet werden. In diesem Teil der Abfrage bezieht sich ?Person auf die gesuchte Entität, die in der ersten Zeile als Variable definiert wurde, Q145 referenziert das Objekt “United Kingdom” und P106 repräsentiert das Prädikat “country of citizenship”. Die Eigenschaften von Objekten und Prädikaten (z.B. Bezeichner in anderen Sprachen) können auf der Wikidata-Seite zum Objekt (hier Q1456) oder zum Prädikat (hier P1067) eingesehen werden.
Das Ergebnis8 der Abfrage ist (erstellt am 26. September 2018) eine Liste von 71 Personen, beginnend mit den folgenden 4 Personen:
Wikidata-ID
Personenname (WikidataLabel)
GND-ID
1. wd:Q334846
Edmund Allenby, 1st Viscount Allenby
119161311
2. wd:Q722472
Homer H. Dubs
11623167X
3. wd:Q725050
John Burnet
117175056
4. wd:Q310794
Karl Pearson
118982141
Dieses Ergebnis diente der vorläufigen Einschränkung des Suchraumes mit Hilfe logisch-semantischer Bedingungen. Im Folgenden wird gezeigt, wie dieses Ergebnis mit Hilfe einer konkreten Abfrage in Bezug auf Bestandsobjekte von GLAMs bzw. hier konkret in Bezug auf Werke einer Bibliothek genutzt werden kann.
Suche nach Unterbegriffen
Im letzten Abschnitt haben wir ein Suchbeispiel vorgestellt, in welchem nach einer Person gesucht wird. Stellen wir uns nun vor, dass wir spezifischer nach einem Autor suchen, der ein Werk verfasst hat, das inhaltlich im Feld der Logik angesiedelt ist, und dass wir aufgrund der Spezialisierung davon ausgehen können, dass eines der in relevanten Werken vergebenen Schlagworte ein Unterbegriff von Logik (z.B. Aussagenlogik, Prädikatenlogik, etc.) ist. Im deutschen Sprachraum findet die sogenannte Gemeinsame Normdatei (GND) verbreitet Anwendung. Diese ist nicht nur eine Begriffssammlung, sondern stellt zugleich auch eine Ontologie dar. Diese ermöglicht es uns beispielsweise innerhalb der Sachschlagwörter der GND nach über- oder untergeordneten Begriffen zu recherchieren. Mit der Plattform lobid.org steht eine frei nutzbare REST-API9 zur Verfügung, die es erlaubt, die GND maschinenlesbar abzufragen. Dies ermöglicht bei Kenntnis der Feldstruktur eines indexierten Dokumentes, den Aufbau komplexer Suchabfragen durch Eingabe der jeweiligen Feld-/”Spalten”namen.10
An die REST-Schnittstelle von lobid.org werden hier drei Paramter übergeben:
q: übergibt die eigentliche Suchabfrage.
type=SubjectHeading – sucht nach GND-Einträgen die Sachschlagwörter darstellen
broaderTermGeneral.label=Logik sucht nach Einträgen deren übergeordneter Begriff Logik enthält.
format: definiert das auszugebende Format des Ergebnisses
size: Anzahl der zurückgegebenen Treffer einer Anfrage
Aus dem Ergebnis kann für die weiterführende Suche im Zielkatalog je nach Sinnhaftigkeit und Einsatzmöglichkeit der Identifier des Begriffes oder aber auch die Ansetzungsform des Schlagwortes verwendet werden.
Verknüpfung der Personen- mit der Schlagwortsuche
Die in den beiden zuvor gezeigten Schritten maschinenlesbar gewonnen Ergebnisse erlauben nun die anfänglich unscharfe Suchabfrage in Form eines Suchbefehls zu bringen, der die einzelnen Schlagwörter mit den jeweiligen Autoren kombiniert, idealerweise sogar ausschliesslich durch die Verwendung von Identifikatoren der im Zielkatalog der Institution eingesetzten Normdatei.
Eine Voraussetzung für die Implementierung ist, dass für die in den Bestandsmetadaten existierenden Schlagworte die entsprechenden GND Identifier angereichert werden. Bezüglich der methodisch vergebenen Sachschlagwörter kann eine eindeutige Zuweisung durch die Lobid-Abfrage erreicht werden. Kommen jedoch frei vergebene Schlagworte oder Personennamen hinzu, so müssen die Terme eventuell durch Hinzuziehen vonKontext-Informationen disambiguiert werden. Die Anreicherung der Metadaten mit Schlagwort-GND-Identifiern kann unabhängig von der späteren Abfrage auf dem gesamten Metadatenbestand im Vorhinein durchgeführt werden.
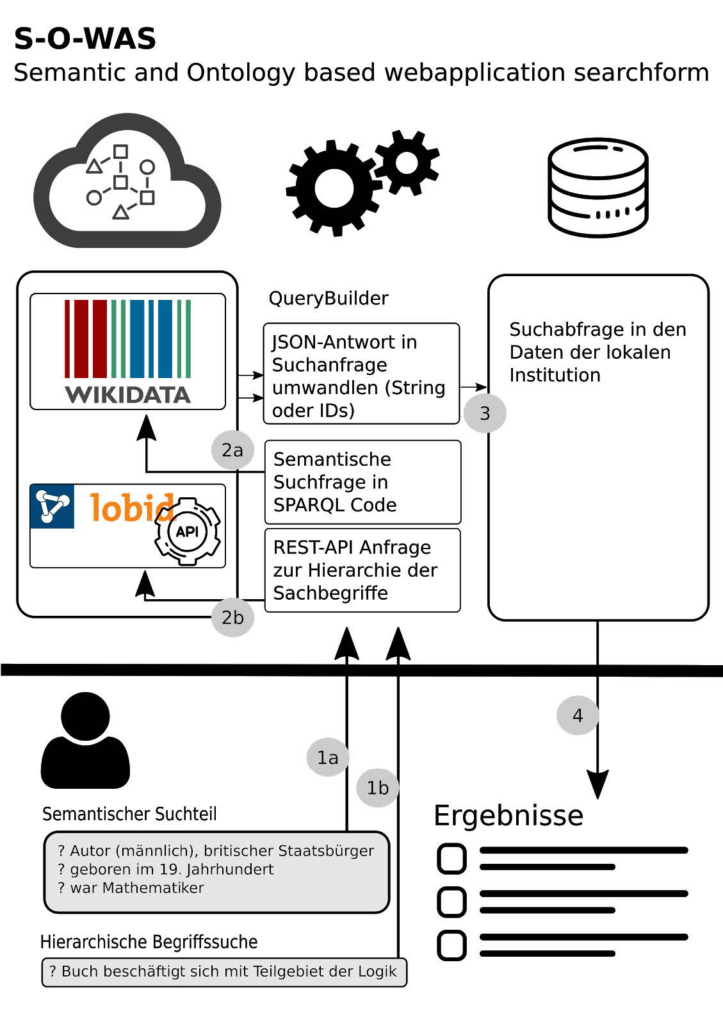
In Abbildung 2 wird der Ablauf beginnend von der Formulierung der Suchanfrage bis zur Ergebnisdarstellung schematisch dargestellt. Der horizontale Querbalken im unteren Bereich der Grafik stellt die Systemgrenze dar. Die oder der BenutzerIn formuliert eine Abfrage mit den semantischen Bedingungen und dem konkreten Begriff zu einem Sachgebiet.
Der QueryBuilder ist eine Komponente, die aus der Suchanfrage die Systemanfragen sowohl an die lobid-API als auch an Wikidata generiert.
Die Semantische Abfrage wird als SPARQL-Abfrage an die Wikidata geschickt (Schritt 1a und 2a in Abbildung 2), die als Ergebnis die Menge der Wikidata-Identifier IP der Menge der Personen P=(p1, p2, …, pn) liefert, die den semantischen Kriterien entsprechen.
IP=(gndp1, gndp2, …, gndpn)
Im ersten Schritt wird die Menge der GND-Identifier I der Unterbegriffe Us=(u1, u2, …, un) zum Themengebiet s (in diesem Beispiel s=»Logik») mit Hilfe der lobid-API in Form einer REST-Abfrage ermittelt (Schritt 1b und 2b in Abbildung 2).
IUs=(gndu1, gndu2, …, gndun)
Unter der Voraussetzung, dass in den Metadaten eines Bestandsobjekts r die GND-Identifier IAr für Personen (=AutorInnen) und die GND-Identifier ISr für Sachschlagworte zugewiesen sind, ist die Ergebnismenge R=(r1, r2, …, rn) der Bestandsobjekte dadurch definiert, dass mindestens ein Autor ip unter den Autoren schlagworten IAr und mindestens ein Unterbegriff iu unter den Schlagworten ISr in den Metadaten des Bestandsobjekts vorhanden sein muss (Schritt 3 und 4 in Abbildung 2):
R = {r | Ǝ ip ∈ IAr ∧ Ǝ iu ∈ ISr r}
Abbildung 2: Schema der Generierung eine Suchmaschine mittels Linked Open Data Quellen
Verwandte Arbeiten
Die Verwendung von Wikidata zur Community-basierten Zuordnung von Namen und anderen Entitäten aus Normdateien wurde von Joachim Neubert vorgestellt (Neubert, 2017). Der wesentliche Unterschied ist, dass die externen Identifier selbst, die eine Organisation verwaltet, in die Wikidata integriert werden. Auf diese Weise können dann Links zurück auf das Bestandsobjekt im Katalog generiert werden (Lemus-Rojas et al., 2018).
Ausblick
Die während des zweiten openglam.at Kulturhackathons 201811 entstandenen und hier dargestellten konzeptuellen Überlegungen zeigen die Innovationspotentiale von Linked Open Data (LOD) in GLAM-Institutionen auf, und zwar in der Verbindung zwischen externen LOD-Quellen und lokalen, klassischen textbasierten Suchmöglichkeiten der jeweiligen Institutionen. Letztere haben durch ihre langjährige Erfahrung und den Einsatz normierter Datenbestände wie der gemeinsamen Normdatei (und ihrer Vorgängerkorpora) eine nicht zu unterschätzende Grundlage für die Kopplung an moderne Open Data Tools geschaffen.
Die freie Wissensdatenbank Wikidata erlaubt mit SPARQL auch komplexe Anfrage formulieren zu können und bietet die Möglichkeit GND-IDs als Antwort zu senden. Mit der freien Plattform lobid.org/gnd kann die GND selbst auf simple Art und Weise auch in ihrer Ontologie maschinenlesbar durchsucht werden. Eine Query-Builder-Applikation steuert entsprechende Anfragen und bereitet diese vor, kombiniert die aus LOD-Cloud stammenden Antworten und baut eine Suchabfrage an den lokalen Bestandskatalog vor.
2 Im Bibliotheksbereich gelten beispielsweise für die formale Katalogisierung RDA (Ressource Description and Access) oder RAK (Regeln für den alphabetischen Katalog) oder für die inhaltlichen Beschreibung RSWK (Regeln für den Schlagwortkatalog).
Faden, Manfred; Gross, Thomas: Automatische Indexierung elektronischer Dokumente an der Deutschen Zentralbibliothek für Wirtschaftswissenschaften. In: Bibliotheksdienst 44 (2010), Nr. 12, S. 1120 – 1135.
Lemus-Rojas, M., Pintscher, L. (2018). Wikidata and Libraries: Facilitating Open Knowledge. In M. Proffitt (Ed.), Leveraging Wikipedia: Connecting Communities of Knowledge (pp. 143-158). Chicago, IL: ALA Editions.
https://www.societybyte.swiss/wp-content/uploads/2018/10/shutterstock_789759175_ret-scaled.jpg11851920Christian Erlinger-Schiedlbauerhttps://www.societybyte.swiss/wp-content/uploads/2023/05/logo-societybyte-DE.webpChristian Erlinger-Schiedlbauer2018-10-24 13:19:322018-12-11 12:09:27Semantische Suchabfragen mit der Linked Open Data Cloud generieren
Die SBB arbeitet eng mit der Open-Data-Community zusammen. Seit knapp zwei Jahren stehen auf der Open-Data-Plattform öV Schweiz Fahrplan-Angaben und Echtzeit-Informationen zur Verfügung. Diese Daten nutzen die Kundinnen und Kunden via praktischen Apps etwa zu Verspätungen und Haltestellen, erläutert unsere Autorin und Verantwortliche bei der SBB Rahel Ryf.
Bereits nach kurzer Zeit hat das Open Data Engagement von SBB und BAV Früchte getragen. Die Daten können Kundinnen und Kunden in mehreren Anwendungen nutzen.
Nach der Eingabe eines Stationsnamens informiert der Bot über eventuelle Verzögerungen. Der Clou: Der Roboter wird die Station auch für die nächste Stunde überwachen und auf Verspätungen prüfen. Wenn sich etwas ändert, wird automatisch eine Benachrichtigung versendet.
Swiss Transit App, Vasile Coțovanu – erhältlich im iTunes Store
Swiss Transit App ist der perfekte Reisebegleiter für die Reise in die Schweiz. Sie umfasst mehr als 24’000 Bahnhöfe und mehr als eine Million Fahrzeuge: Züge, Strassenbahnen, Busse, Boote und sogar Gondeln und Seilbahnen. Besonders wichtig: Sämtliche Funktionen sind offline verfügbar. Auch ohne Internetverbindung kann nach Stationen oder Abfahrten gesucht werden.
Pünktlichkeit gehört zu den Erfolgsfaktoren des öffentlichen Verkehrs. Und im besonders erfolgreichen Schweizer öV ist die Pünktlichkeit besonders hoch. Wie hoch sie tatsächlich ist und wo es vielleicht doch hin und wieder zu Verspätungen kommt, will puenktlichkeit.ch zeigen. Die Website ist im Rahmen des MAS-Studiengangs «Data Science» an der Berner Fachhochschule entstanden und wird privat betrieben.
Der Open Data Show Room der Forschungsstelle Digitale Nachhaltigkeit präsentiert Applikationen zur interaktiven Datenvisualisierung. Studierende haben die meist D3.js-basierten Web-Anwendungen im Rahmen der Open Data Vorlesung entwickelt. Die Veranstaltung der Universität Bern findet am Institut für Wirtschaftsinformatik statt und hat seit 2014 Dutzende aussagekräftiger Open Data Visualisierungen hervorgebracht. Die Apps verschaffen durch kreative Darstellungsarten einen verständlichen und transparenten Zugang zu komplexen Daten.
Rome2rio macht die Reiseplanung einfach. Es handelt sich um eine Reiseinformations- und Buchungsmaschine von Tür zu Tür, die hilft, von und zu jedem Ort der Welt zu gelangen. Nach Eingabe eines beliebigen Ortes zeigt Rome2rio alle Reise- und Buchungsmöglichkeiten sowie Informationen über Unterkunft und Aktivitäten an Ort an. Egal, ob Informationen zu Flug, Zug, Bus, Fähre, Mitfahrgelegenheit oder Mietwagen gewünscht werden, Rome2rio hat geschätzte Preise, Reisedauer und Buchungsdetails von über 5000 Unternehmen in mehr als 160 Ländern – das macht Rome2rio zu einem der führenden Online-Reisebüros weltweit.
FAIRTIQ ist eine Mobile Ticketing Applikation für den öffentlichen Verkehr und funktioniert nach dem CIACO-Prinzip (Check In – Assisted Check Out). Vor der Reise mit dem öV checkt der Kunde mit einem Klick ein und erhält dadurch ein gültiges Ticket für den gesamten Verbund. Nach der Reise checkt man mit einem weiteren Klick wieder aus. Das System erkennt dank Standortermittlung des Mobiltelefons die gefahrene Strecke und verrechnet im Anschluss das passende Ticket auf das hinterlegte Zahlungsmittel.
Ein Tool für alle Benutzer des öffentlichen Verkehrsnetzes der Schweiz. Die App weiss, wann der gewünschte Bus, das Tram oder der Zug abfährt und zeigt den entsprechenden Countdown an. Es können Favoriten angelegt und Strecken überwacht werden.
ÖV AR, Lukas Gasser – erhältlich im iTunes Store
Mit ÖV AR sieht man die nächsten Haltestellen in der Umgebung durch die Linse der iPhone-Kamera. Es wird neben Name und Art der Haltestelle auch die Distanz zur Haltestelle angezeigt. Die gewünschte Haltestelle kann angetippt werden, um eine Übersicht mit den nächsten Abfahrten einzublenden. Auch die verfügbaren Bike-Sharing-Stationen in der Umgebung werden angezeigt
Urbane Herausforderungen werden zu Datenverfügbarkeitsproblemen
Multimodale Mobilitätsdienstleistungen sind die Zukunft. Durch die Digitalisierung können unterschiedliche Transportarten einfacher und gezielter kombiniert werden. Die Digitalisierung wird viel mehr Transparenz schaffen und Kaufentscheide werden immer öfter im digitalen Kanal getroffen. Die KundInnen entscheiden sich für die günstigste, bequemste, schnellste und vor allem die einfachste Art, um von A nach B zu reisen. Sie werden für sich selbst das beste persönliche Gesamtangebot finden.
Mit dem Wandel des Mobilitätsmarkts entstehen neue Angebote und neue Optionen für die Reisenden. Das öV Netz wird sich bezüglich der Möglichkeiten, um von A nach B zu reisen, vervielfachen und die Infrastruktur kann optimaler genutzt werden. Konsequenz ist eine grössere Wahl bei den Mobilitätsdienstleistungen. Die Einfachheit wird der Schlüsselfaktor sein. Urbane Herausforderungen werden zu Datenverfügbarkeitsproblemen und um diese Potentiale zu entfalten und die Risiken zu mildern, braucht es optimale Rahmenbedingungen. Im Zentrum steht der Zugang zu Mobilitäts- und Verkehrsdaten, wie es auf der Open-Data-Plattform öV Schweiz ermöglicht wird.
Als grosses Unternehmen, müssen die SBB für Innovation offen sein und sicherstellen, dass auch mal umgekehrt werden kann, um einer neuen Richtung zu folgen. Nur so, kann man einer Kraft, welche die Zukunft gestaltet, beitreten ohne dabei von der Zukunft überholt zu werden. Innovation und Transparenz sind heute so wichtig wie nie Wie die bereits entstandenen Showcases beweisen, ist Open Data ein Weg dies zu fördern.
Die Publikation von Echtzeitdaten mittels API war ein grosser und wichtiger Schritt. Es ist ein grosser Meilenstein für Open Data in der Schweiz aber auch darüber hinaus. Die Schweiz ist ein öV-Land, opentransportdata.swiss soll dazu beitragen, dass die SBB auch im digitalen Zeitalter Leader und Innovator sind.
Weitere Informationen
Fahrplan-Angaben und Echtzeit-Informationen zum öffentlichen Verkehr in der Schweiz sind seit Dezember 2016 auf einer Plattform verfügbar. Sie wurde von der SBB im Auftrag des Bundes erstellt. Die Daten ermöglichen es sowohl den Transportunternehmen als auch Unternehmen von ausserhalb der Transportbranche, neue Kundeninformationssysteme, neue Apps oder andere Anwendungen für die Information der Reisenden zu entwickeln.
Das Bundesamt für Verkehr (BAV) hat die SBB als Systemführerin damit beauftragt, eine Open-Data-Plattform für den gesamten Schweizer öV aufzubauen und zu betreiben. Die Open-Data-Plattform öV Schweiz stellt alle von den beteiligten konzessionierten Transportunternehmen gelieferten Fahrplandaten sowie die aktuelle Verkehrslage des öffentlichen Verkehrs in Echtzeit zur Verfügung. Nutzer sind Unternehmen und Startups, welche die Daten aufbereiten und Kundeninformationen für Reisende zusammenstellen. Im Sinne der bundesrätlichen «Open-Data»-Strategie und als Beitrag bei der Umsetzung der Strategie «Digitale Schweiz» des UVEK, werden so Innovationen durch die Privatwirtschaft erleichtert und gefördert.
Wir können Cookies anfordern, die auf Ihrem Gerät eingestellt werden. Wir verwenden Cookies, um uns mitzuteilen, wenn Sie unsere Websites besuchen, wie Sie mit uns interagieren, Ihre Nutzererfahrung verbessern und Ihre Beziehung zu unserer Website anpassen.
Klicken Sie auf die verschiedenen Kategorienüberschriften, um mehr zu erfahren. Sie können auch einige Ihrer Einstellungen ändern. Beachten Sie, dass das Blockieren einiger Arten von Cookies Auswirkungen auf Ihre Erfahrung auf unseren Websites und auf die Dienste haben kann, die wir anbieten können.
Wichtige Website Cookies
These cookies are strictly necessary to provide you with services available through our website and to use some of its features.
Because these cookies are strictly necessary to deliver the website, refusing them will have impact how our site functions. You always can block or delete cookies by changing your browser settings and force blocking all cookies on this website. But this will always prompt you to accept/refuse cookies when revisiting our site.
We fully respect if you want to refuse cookies but to avoid asking you again and again kindly allow us to store a cookie for that. You are free to opt out any time or opt in for other cookies to get a better experience. If you refuse cookies we will remove all set cookies in our domain.
We provide you with a list of stored cookies on your computer in our domain so you can check what we stored. Due to security reasons we are not able to show or modify cookies from other domains. You can check these in your browser security settings.
Google Analytics Cookies
These cookies collect information that is used either in aggregate form to help us understand how our website is being used or how effective our marketing campaigns are, or to help us customize our website and application for you in order to enhance your experience.
If you do not want that we track your visit to our site you can disable tracking in your browser here:
Andere externe Dienste
We also use different external services like Google Webfonts, Google Maps, and external Video providers. Since these providers may collect personal data like your IP address we allow you to block them here. Please be aware that this might heavily reduce the functionality and appearance of our site. Changes will take effect once you reload the page.
Google Webfont Settings:
Google Map Settings:
Google reCaptcha Settings:
Vimeo and Youtube video embeds:
Other cookies
The following cookies are also needed - You can choose if you want to allow them:


 Create PDF
Create PDF













 Beiträge als RSS
Beiträge als RSS