
Unternehmen setzen vermehrt Künstliche Intelligenz (KI) ein, um Entscheidungen zu treffen oder basierend auf deren Vorschlägen zu entscheiden. Diese Vorschläge können auch diskriminierend sein. Um dies zu verhindern, müssen wir nicht nur Programmcodes auf technischer Ebene verstehen, sondern auch menschliche Denkweisen und Entscheidungsprozesse einbeziehen, um systematische Täuschungen zu erkennen und zu reduzieren. CO-Autorin Thea Gasser schlägt dazu Hilfsmittel und Vorgehensweisen in ihrer Bachelorthesis [1] vor, die kürzlich auf der TDWI-Konferenz in München mit einem Preis ausgezeichnet wurde.
In letzter Zeit wächst die Sorge über unfaire Entscheidungen, die mit Hilfe von algorithmischen Systemen getroffen werden und die zu Diskriminierung von sozialen Gruppen oder Einzelpersonen führen. Beispielsweise wird Googles Werbesystem vorgeworfen, einkommensstarke Jobs vorwiegend männlichen Nutzern anzuzeigen. Auch Facebook’s automatischer Übersetzungsalgorithmus hat 2017 für Aufsehen gesorgt, als dieser eine falsche Übersetzung für einen Benutzerbeitrag wählte, was dazu führte, dass die Polizei den betroffenen Benutzer verhörte [2]. Oder Seifenspender, die für Menschen mit dunkler Haut nicht funktionieren [3]. Darüber hinaus sind verschiedene Fälle bekannt, bei denen selbstfahrende Autos Fussgänger oder Fahrzeuge nicht erkennen konnten, was zum Verlust von Menschenleben führte [4].
Die aktuelle Forschung zielt darauf ab, menschliche Intelligenz auf KI-Systeme abzubilden. Robert J. Steinberg [5] definiert menschliche Intelligenz als «…mentale Kompetenz, die aus den Fähigkeiten besteht, aus Erfahrung zu lernen, sich an neue Situationen anzupassen, abstrakte Konzepte zu verstehen und zu beherrschen und Wissen zu nutzen, um das eigene Umfeld zu verändern.» Bis heute fehlen KI-Systemen jedoch beispielsweise die menschliche Eigenschaft Selbstwahrnehmung. Die Systeme sind immer noch auf menschliche Eingaben in Form von erstellten Modellen und ausgewählten Trainingsdaten angewiesen. Dies impliziert, dass teilweise intelligente Systeme von den Ansichten, Erfahrungen und Hintergründe des Menschen stark geprägt sind und somit auch kognitive Verzerrungen aufweisen können.
Dabei werden Verzerrungen (engl.: Bias) als «…die Handlung eine bestimmte Person oder eine Sache auf eine unfaire Art und Weise zu unterstützen oder sich ihr zu widersetzen, dadurch dass zugelassen wird, dass persönliche Meinungen das Urteilsvermögen beeinflussen» definiert [6]. Ursachen für kognitive Verzerrungen im menschlichen Denkprozess und in Entscheidungsfindungen sind Informationsüberflutung, Bedeutungslosigkeit der Information, die Notwendigkeit schnell zu handeln, oder Unsicherheit darüber, woran man sich später erinnern muss und was vergessen werden kann [7]. Als Folge kognitiver Verzerrungen lassen sich Menschen unbewusst täuschen und erkennen möglicherweise nicht die fehlende Objektivität ihrer Schlussfolgerungen [8]
Die Erkenntnisse der Bachelorarbeit der Co-Autorin mit dem Thema «Bias – A lurking danger that can convert algorithmic systems into discriminatory entities» (1) haben zunächst gezeigt, dass Verzerrungen in algorithmischen Systemen eine Quelle für unfaire und diskriminierende Entscheide sind. Weiterhin resultiert aus der Arbeit ein Framework, welches zur KI-Sicherheit beitragen soll, indem es Massnahmen vorschlägt, die zur Identifizierung und Minderung von Verzerrungen während der Entwicklungs-, Implementierungs- und Anwendungsphase von KI-Systemen beitragen. Das Framework besteht aus einem Metamodell, das 12 wesentliche Bereiche umfasst (z.B. «Project Team», «Environment and Content» etc.) und den gesamten Software-Lebenszyklus abdeckt (siehe Abb. 1). Für jeden der Bereiche steht eine Checkliste zur Verfügung, durch deren Anwendung die Bereiche vertieft betrachtet und analysiert werden können.
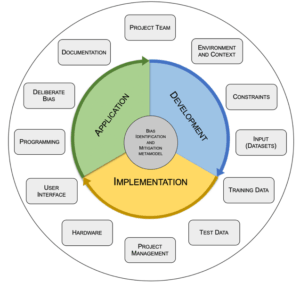
Abbildung 1: Metamodell des Bias Identification and Mitigation Frameworks
Als Beispiel wird im Folgenden der Bereich «Project Team» näher erläutert (siehe Abb. 2). Wissen, Ansichten und Einstellungen einzelner Teammitglieder können nicht gelöscht oder ausgeblendet werden, da es sich hierbei in der Regel um unbewusste Faktoren handelt, die auf den unterschiedlichen Hintergrund und die vielseitigen Erfahrungen jedes einzelnen Mitglieds zurückzuführen sind. Die resultierende Verzerrung wird wahrscheinlich in das algorithmische System übertragen.

Abbildung 2: Checklistenausschnitt für den Bereich «Projektteam» des Metamodells
Daher müssen Maßnahmen ergriffen werden, damit das System die dem Kontext entsprechende Fairness aufweist. Es ist notwendig, dass es einen Austausch unter den Projektmitgliedern gibt, bei dem jede/r ihre/seine Ansichten und Anliegen offen, vollständig und transparent teilt, bevor das System gestaltet wird. Missverständnisse, Konfliktvorstellungen, zu viel Euphorie und unbewusste Annahmen oder unsichtbare Aspekte können so aufgedeckt werden. Die Checkliste für den Bereich «Project Team» enthält die folgenden konkreten Maßnahmen zur Lösung der oben genannten Probleme:
Alle Projektmitglieder (1) haben an Schulungen zum Thema Ethik teilgenommen, (2) sind sich des Themas Bias bewusst, das im menschlichen Entscheidungsprozess existiert, (3) wissen, dass Bias in einem algorithmischen System reflektiert werden kann und (4) betrachten im Systemkontext die gleichen Attribute und Faktoren als am meisten relevant. Das Projektteam (1) spiegelt Vertreter aller möglichen Endnutzergruppen wieder, (2) ist ein funktionsübergreifendes Team mit Diversität in Bezug auf Ethnizität, Geschlecht, Kultur, Bildung, Alter und sozioökonomischen Status, und (3) besteht aus Vertretern des öffentlichen und privaten Sektors.
In der Bachelorarbeit der Co-Autorin sind Checklisten für alle im Metamodell aufgeführten genannten Bereiche enthalten. Basierend auf den Ergebnissen der Arbeit soll das Framework ein initialer Rahmen sein, der an die spezifischen Bedürfnisse in einem gegebenen Projektkontext angepasst werden kann. Der vorgeschlagene Ansatz hat die Form einer Richtlinie z.B. für die Mitglieder eines Projektteams. Die Anpassungen des Frameworks können auf der Grundlage eines definierten Verständnisses von Systemneutralität vorgenommen werden, welches für die jeweilige Anwendung oder Anwendungsdomäne spezifisch sein kann. Wenn das auf den jeweiligen Kontext angepasste Framework in einem verpflichtenden Rahmen innerhalb eines Projekts verwendet wird, ist es sehr wahrscheinlich, dass die entwickelte Anwendung die vom Projektteam oder Unternehmen definierte Neutralität besser widerspiegelt. Die Prüfung, ob das Framework angewendet und die Anforderungen eingehalten wurden, hilft herauszufinden, ob das System den definierten Neutralitätskriterien gerecht wird oder ob und wo Handlungsbedarf besteht.
Um Verzerrung in algorithmischen Systemen angemessen anzugehen, muss in Unternehmen, in denen KI-Verantwortung ernst genommen wird, eine übergreifende und umfassende Governance vorhanden sein. Im Idealfall verinnerlichen Projektmitglieder das Framework und betrachten es als verbindlichen Standard.
Referenzen
- Gasser, T. (2019). Bias – A lurking danger that can convert algorithmic systems into discriminatory entitie: A framework for bias identification and mitigation. Bachelor’s Thesis. Degree Programme in Business Information Technology. Häme University of Applied Sciences.
- Cossins, D. (2018). Discriminating algorithms: 5 times AI showed prejudice. Retrieved January 17, 2019.
- Plenke, M. (2015). The Reason This «Racist Soap Dispenser» Doesn’t Work on Black Skin. Abgerufen 20. Juni 2019.
- Levin, S., & Wong, J. C. (2018). Self-driving Uber kills Arizona woman in first fatal crash involving pedestrian. The Guardian. Retrieved February 17, 2019.
- Sternberg, R. J. (2017). Human intelligence. Retrieved June 20, 2019.
- Cambridge University Press. (2019). BIAS | meaning in the Cambridge English Dictionary. Retrieved June 20, 2019.
- Benson, B. (2016). You are almost definitely not living in reality because your brain doesn’t want you to. Retrieved June 20, 2019.
- Tversky, A., & Kahneman, D. (1974). Judgment under Uncertainty. Heuristics and Biases. Science, New Series, 185(4157), 1124-1131.
 Create PDF
Create PDF



 Illustration 1
Illustration 1 Illustration 2
Illustration 2



 Beiträge als RSS
Beiträge als RSS