Wir leben in einer Gesellschaft, in der die Medienvielfalt unser kommunikatives Handeln nicht nur beeinflusst, sondern auch steuert. Das mit dem Buchdruck begann, wird in Zukunft vielleicht mit Robotern weitergeführt: Die Digitalisierung ist nicht mehr wegzudenken – auch nicht bei einer Profession, bei der der Mensch im Mittelpunkt steht.
Um die Sozialhilfegelder für den kommenden Monat zu bekommen, muss die Klientin online einen kurzen Fragebogen ausfüllen. Sie kann dies auf ihrem Smartpho- ne tun oder auf jedem anderem Gerät, das mit dem Internet verbunden werden kann. Ihr Sozialarbeiter, der die Zahlung prüft, heisst Avo. Avo ist braunhaarig, hat grüne Augen und eine ruhige Stimme, er ist einfühlsam und hilfsbereit. Er kann jede Frage beantworten, sei es eine rechtliche oder eine zu einem familiären Problem. Und er ist jederzeit verfügbar. Avo ist eine wichtige Ansprechperson für die Klientin geworden, er existiert – jedoch nur virtuell. Er ist eine intelligente Weiterentwicklung der heute üblichen Avatare.
Was heute noch etwas merkwürdig anmuten mag, könnte ein Zukunftsszenario der wirtschaftlichen Sozialhilfe sein. Wie Bancomaten die Schalterfrauen und -männer in den Banken ersetzt haben, könnten Avatare oder Roboter vielleicht bald die Sozialarbeitenden in der Beratung ersetzen. Eine Studie geht davon aus, dass 47 Prozent der aktuellen Arbeitsplätze in den USA in den nächsten ein bis zwei Jahrzehnten infolge der Digitalisierung ersetzt werden (vgl. Frey & Osborne, 2013, S. 38 ff.). Würde dieses Szenario auf die Schweiz zutreffen, hätten die Fachpersonen der Sozialen Arbeit nicht nur mit einer grösseren Anzahl Klientinnen und Klienten zu tun, sie würden eventuell gar selber zu dieser Klientel gehören. Noch sind wir zwar nicht soweit. Die Mediatisierung, also die «zeitliche, räumliche und soziale Durchdringung des Alltags mit Medien» (Nadia Kut- scher, Thomas Ley & Udo Seelmeyer, 2015, S. 3), und die Digitalisierung unseres Lebens bergen jedoch neue Herausforderungen für die Soziale Arbeit. Sie eröffnen aber auch Chancen.
Vom Buchdruck zur «Liquid Democracy»
Mit der Erfindung des Buchdruckes im 15. Jahrhundert wurde es möglich, Informationen schriftlich in Massenauflagen zu veröffentlichen. Dies bedeutete auch, dass die Informationsmacht im Laufe der Zeit immer weiter demokratisiert wurde – bis zum heutigen Inter-net, in dem jede und jeder publizieren kann. Wobei die «Liquid Democracy», die flüssige Demokratie, die eine Mischung aus direkter und repräsentativer Demokratie darstellt, wie sie das Internet ermöglicht, nicht unumstritten ist (vgl. Passig & Lobo, 2012). Doch ihre massive Wirkung ist klar ersichtlich, wie nicht zuletzt das Beispiel der «Panama Papers» zeigte: Eine Gruppe von Journalistinnen und Journalisten konnte durch weltweite Vernetzung ein Datenleck nutzen und eine Unmenge von Daten aufbereiten und über diverse Medien zeitgleich veröffentlichen; mit einschneidenden Folgen für die Anbietenden von Offshore-Dienstleistungen und deren Kundinnen und Kunden.
Veränderter Umgang mit Daten
Die unglaubliche Menge an Daten, auch «Big Data» genannt, die online abgelegt sind, werden unterschiedlich behandelt. Manche Daten über uns stellen wir selbst frei zugänglich ins Netz, wie zum Beispiel unsere Adresse und Telefonnummer auf den virtuellen «Gelben Seiten» oder über einen eigenen Blog. Andere Daten von uns landen im Netz, ohne dass wir es wissen, beispielsweise über Protokolle der Vereins-Mitarbeit, Social-Media-Plattformen oder durch Websites unserer Arbeitgebenden. Weitere Daten würden wir nie veröffentlichen und wir wünschen, dass sie sicher verwaltet werden, wie etwa die Inhalte unseres Online-Banking-Accounts.
Auch Klientinnen und Klienten der Sozialen Arbeit wünschen, dass die Daten, die wir über sie sammeln, vertrauenswürdig bearbeitet und abgelegt werden. Die genutzte Informatik-Infrastruktur sollte in einer sicheren Umgebung eingebettet sein, sie soll Angriffen von aussen standhalten. Weiter dürfen nur befugte Mitarbeitende Zugriff auf die Daten haben. Die Daten – sowohl in Papier- als auch in elektronischer Form – müssen vernichtet werden, wenn sie nicht mehr benötigt werden (vgl. dazu das Datenschutzgesetz des Kantons Bern).
Ein Zukunftsszenario könnte sein, dass die Klientinnen und Klientinnen sich ihre Daten zu Nutze machen: So wie heute einige Krankenkassen ihren Versicherten für einen Bonus anbieten, ihre Gesundheitsdaten freiwillig festzuhalten und wiederum den Kassen zur Verfügung zu stellen, könnten in Zukunft vielleicht die Klientinnen und Klienten einen direkten oder indirekten Nutzen aus den Daten generieren, die sie den Sozialarbeitenden zur Verfügung stellen.
Zwischen Kontaktaufnahme und Datenschutz
Besonders Fachpersonen der Sozialen Arbeit, die mit der jüngeren Klientel zu tun haben, stellen sich tagtäglich neue Herausforderungen: Jugendarbeiterinnen und Jugendarbeiter in der Soziokulturellen Animation müssen sich sowohl mit oft wechselnden Social-Media-Platt- formen (wie Facebook, SnapChat, Twitter, etc.) auskennen und ihr Publikum online auf dem gerade angesagten Medium abholen. Gleichzeitig müssen sie den Datenschutz berücksichtigen. Denn nicht jeder Kontakt, der online hergestellt werden kann, darf auf der jeweiligen Plattform weitergeführt werden. In der Arbeit mit Kindern und Jugendlichen stellen sich – im Unterschied zur den oft gut geregelten Informatik-Lösungen in der Sozialarbeit mit Erwachsenen – laufend Fragen zum Einsatz von neuen Medien. Mitarbeitende benötigen hohe Medienkompetenzen, die Leitung muss sich strategischen Fragen zum Einsatz von Social Media stellen.
Neue Beratungsformen senken die Hemmschwelle
Eine Vorreiterin in der Online-Beratung ist die Stiftung Pro Juventute, die auf eine über 100-jährige Geschichte zurückblicken kann. 1970 versendete Pro Juventute erstmals Elternbriefe, ab 1992 gab es das «Help- o-Fon», ab 1999 die Nummer 147 mit einer während 24 Stunden und 365 Tagen erreichbaren Telefonberatung für Kinder und Jugendliche. Heute ist eine ebenfalls rund um die Uhr erreichbare Multi-Channel-Helpline für Kinder, Jugendliche und deren Bezugspersonen in Betrieb.
Beraten wird noch immer über das Telefon, jedoch auch über E-Mail, das Internet, Chat und SMS. Dabei wird zwischen synchroner Beratung (Telefon, Chat) und asynchroner Beratung (Web, E-Mail und SMS) unterschieden. Die verschiedenen Beratungsformen ermöglichen den Ratsuchenden mit ihren Fragestellungen unterschiedliche Zugänge zu Beratung; wobei die eine Beratungsform die andere nicht konkurriert, sondern ergänzt.
Thomas Brunner, Leiter der Pro-Juventute-Beratungsangebote und Lehrbeauftragter an der BFH, sagt dazu: «Lange wurde Telefon- und Onlineberatung als Konkurrenz zur klassischen Face-to-Face-Beratung an- gesehen. Mittlerweile weiss man, dass diese neuen Beratungsformen die Schwelle erheblich senken, über persönliche Fragestellungen und Probleme ‹zu sprechen›. Menschen erhalten so die Möglichkeit, schwierige Themen ohne Gesichtsverlust und ohne Angst vor Stigmatisierung oder anderen negativen Konsequenzen zu bearbeiten.»
Studien bestätigen denn auch, dass Online-Beratung beispielsweise über Video-Chat genau so effektiv ist wie eine Präsenz-Beratung – zudem ist sie günstiger. Diese Erkenntnisse sollte sich die Soziale Arbeit zu Nutze machen, nicht nur hinsichtlich ökonomischer Gesichtspunkte, sondern auch um Menschen, die keine Präsenz-Beratung wünschen, trotzdem zu erreichen. Dass Medienkompetenz und die Weiterentwicklung der Sozialen Arbeit im Zuge der Digitalisierung nicht dem Zufall oder wie selbstverständlich den «Digital Natives» überlassen werden darf, diesem Umstand trägt die BFH Rechnung. Medienkompetenz und Wissen um die Potenziale der Digitalisierung dürfen nicht weiterhin unsystematisch und ausschliesslich aus dem Alltagswissen generiert werden, sondern bedürfen einer Professionalisierung – einerseits um den Klientinnen und Klienten gerecht zu werden und andererseits um den Anforderungen, welche die Digitalisierung und Mediatisierung an die Sozialarbeitenden stellt, vorausschauend begegnen zu können.
Glossar
Avatar
Ein Avatar ist eine Software bzw. ein ExpertInnen-System, das sich in Form einer animierten Person zeigt, teilweise sogar in 3D. Ein Avatar soll im besten Falle Menschen beraten und unterstützen; die heute eingesetzten Avatare sind jedoch noch nicht sehr selbständig. Sie werden in Human- und Agent-Avatar unterschieden. Ein Human-Avatar funktioniert interaktiv: Eine Person spricht durch den Avatar und kann deshalb auf Äusserungen und Aktionen eines Gegenübers reagieren. Human-Avatare haben den Nachteil, dass sie nicht zeit- und personenunabhängig genutzt werden können. Ein Agent-Avatar kann nicht interagieren, er macht nur das, wofür er programmiert ist: Er spricht bzw. reagiert nach Drehbuch. Ein Agent-Avatar ist orts-, zeit- und personenunabhängig einsetzbar.
Digitalisierung
Der Begriff Digitalisierung bezeichnet die Umwandlung analoger Signale in digitale Signale zum Zweck, diese elektronisch zu speichern oder zu verarbeiten. Im weiteren Sinn wird unter Digitalisierung der Wandel hin zu elektronisch gestützten Prozessen mittels Informations- und Kommunikationstechnik verstanden.
Digital Natives und Digital Immigrants
Mit Digital Natives sind die Personen gemeint, die mit der Digitalisierung aufgewachsen sind – als frühster Jahrgang gelten die 1980 geborenen. Die Digital Immigrants sind Personen, die sich erst im Erwachsenenalter mit der Digitalisierung auseinandersetzten.
Literatur
- Frey, Carl Benedikt & Osborne, Michael A. (2013). The Future of Employment: How Sursceptible are Jobs to Computerisation? Abgerufen von http://www.oxfordmartin.ox.ac.uk/publications/view/1314
- Kutscher, Nadia, Ley, Thomas & Seelmeyer, Udo. (2015). Medi- atisierung (in) der Sozialen Arbeit. Baltmannsweiler: Schneider Verlag Hohengehren.
- NZZ Folio. (April 2016). Künstliche Intelligenz. Zürich: NZZ Folio.
- Passig, Kathrin & Lobo, Sascha. (2012.) Internet – Segen oder Fluch? Berlin: Rowohlt.
- Pro Juventute. (2016). Stiftungsgeschichte. Abgerufen von https://www.projuventute.ch/Geschichte.69.0.html
- Süddeutsche Zeitung. (2016). Panama Papers. Die Geheimnisse des schmutzigen Geldes [Website]. Abgerufen von http://panamapapers.sueddeutsche.de/
- Verein sozialinfo.ch. (2013). Soziale Arbeit & Social Media. Leitfaden für Institutionen und Professionelle der Sozialen Arbeit. Bern: Edition Soziothek.
 Create PDF
Create PDF
 Ernst Hafen ist Professor am Institut für Molekulare Systembiologie und ehemaliger Präsident der ETH Zürich. Nebst seinen 26 Jahren in der akademischen Forschung, für die er mit mehreren Preisen ausgezeichnet wurde, setzte er sich aktiv für den Dialog zwischen Forschung und Gesellschaft und für die Umsetzung wissenschaftlicher Erkenntnis in kommerzielle Produkte ein. Als gelernter Genetiker hat Ernst Hafen ein starkes Interesse an der Humangenetik und an der personalisierten Medizin. Er postuliert, dass eine individuelle Kontrolle über persönliche Gesundheitsdaten einen Schlüsselfaktor für eine bessere und effektive Gesundheitsversorgung darstellt. Im Jahr 2012 gründete er den Verein Daten und Gesundheit. Dieser beabsichtigt, die Errichtung einer genossenschaftlich organisierten Gesundheitsdatenbank in der Schweiz zu fördern.
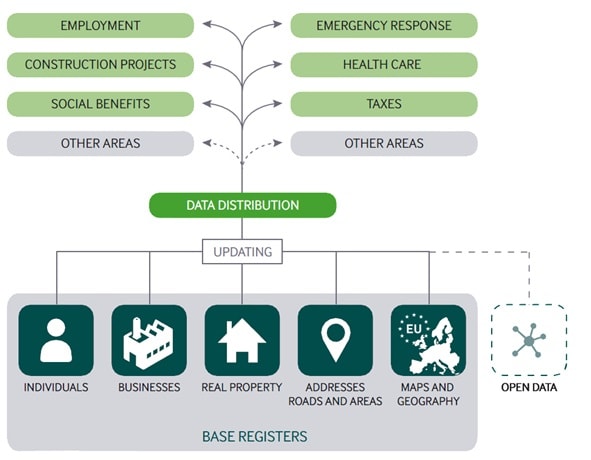
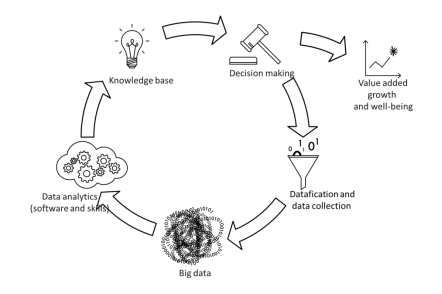
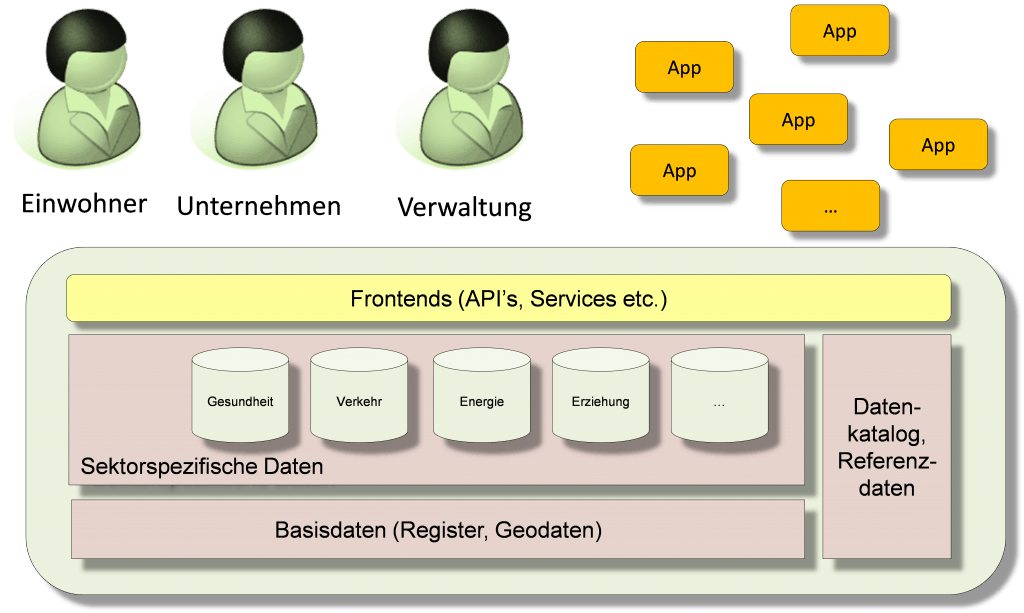
Ernst Hafen ist Professor am Institut für Molekulare Systembiologie und ehemaliger Präsident der ETH Zürich. Nebst seinen 26 Jahren in der akademischen Forschung, für die er mit mehreren Preisen ausgezeichnet wurde, setzte er sich aktiv für den Dialog zwischen Forschung und Gesellschaft und für die Umsetzung wissenschaftlicher Erkenntnis in kommerzielle Produkte ein. Als gelernter Genetiker hat Ernst Hafen ein starkes Interesse an der Humangenetik und an der personalisierten Medizin. Er postuliert, dass eine individuelle Kontrolle über persönliche Gesundheitsdaten einen Schlüsselfaktor für eine bessere und effektive Gesundheitsversorgung darstellt. Im Jahr 2012 gründete er den Verein Daten und Gesundheit. Dieser beabsichtigt, die Errichtung einer genossenschaftlich organisierten Gesundheitsdatenbank in der Schweiz zu fördern.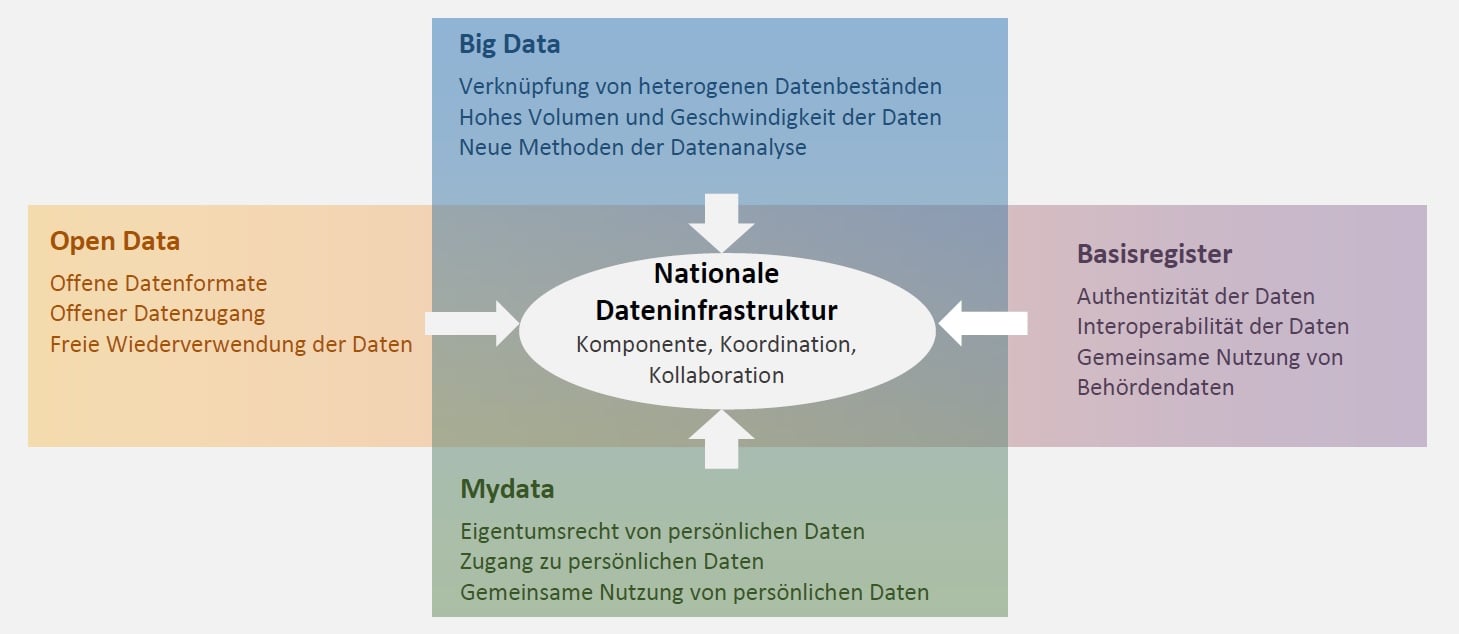
 Beiträge als RSS
Beiträge als RSS