Comment un Triplestore peut publier les données des lacs suisses

L’Office fédéral de l’environnement (OFEV) utilise un TripleStore comme base de données pour publier des données environnementales sur Internet. Cet article montre les avantages qu’une telle technologie peut offrir lors de la création d’un réseau de données environnementales.
En collaboration avec les Archives fédérales (AFS), l’OFEV a mis en service un TripleStore sous lindas.admin.ch et y a publié les premières données environnementales qui peuvent être interrogées à l’aide de SPARQL. Si l’on souhaite aller moins loin sur le plan technique, il est possible de convertir soi-même les données environnementales de Lindas en diagrammes via le site web visualize.admin.ch. Pour ce faire, Visualize accède en direct, via SPARQL, aux triples enregistrés dans Lindas.
En ce qui concerne les URI, nous n’en sommes qu’au début pour les données environnementales. Si d’autres organisations environnementales misent également sur la technologie TripleStore, l’ajout d’URI ne sera qu’un petit pas vers un réseau de données environnementales global. De nombreux outils et bases de données connus utilisent des tableaux comme base de traitement des informations. Par exemple, pour déterminer la qualité de l’eau de baignade dans les lacs, on mesure la concentration de certaines bactéries. Sous forme de tableaux, ces mesures pourraient être publiées comme suit :

La structure choisie pour cet exemple semble intuitive – mais elle a été choisie de manière totalement arbitraire. Il serait envisageable de
- d’omettre la colonne Unité, puisque sa valeur est toujours la même
- de traduire les noms des colonnes en anglais
- d’ajouter d’autres colonnes, comme par exemple la méthode de mesure ou l’emplacement de l’appareil de mesure
La créativité est ici sans limite. Malheureusement, cette flexibilité rend justement difficile la fusion de données provenant de différentes sources.
Les triples représentent une possibilité de modéliser les informations de manière standardisée. Pour ce faire, l’information est divisée en trois domaines (d’où le nom de triple) :
- D’un sujet – le « thème » sur lequel nous voulons dire quelque chose (par ex. les bains du nord)
- Un prédicat (mieux, une propriété ) du sujet (par ex. la date à laquelle une mesure a été prise), et
- Un objet qui contient la valeur de la propriété (par ex. 01.07.2022)
La collection de tous les triples d’informations constitue alors la base de données TripleStore :
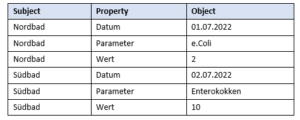
Tous les TripleStores disposent exactement de cette structure – et même si cette structure semble un peu simple au premier abord, elle peut déjà répondre à un certain nombre de questions intéressantes.
- Question : Quels sont les sujets du TripleStore ?
- Réponse : Bains du nord, bains du sud
- Question : Quelles sont les propriétés du Subject Nordbad ?
- Réponse : Date, paramètre, valeur
- Question : Quels paramètres ont été mesurés ?
- Réponse : e.Coli, entérocoques
Sans jamais devoir modifier la structure, il est possible d’ajouter de plus en plus d’informations au fil du temps. Avec un nouveau triple comme (entérocoques, catégorie, bactéries), l’objet entérocoques est maintenant utilisé comme sujet et le nouvel objet bactéries lui est attribué via une propriété « catégorie ». De cette manière, on obtient des graphes complexes qui permettent des requêtes telles que « Quelles bactéries ont été analysées dans la piscine nord ? « . Techniquement, les requêtes adressées au TripleStore sont exprimées dans le langage SPARQL. De manière cohérente, on travaille ici aussi avec des triples. Le modèle suivant (Südbad, Parameter, ?) recherche par exemple tous les objets dont le Subject a la valeur « Südbad » et dont la Property a la valeur « Parameter ». Dans ce cas, la réponse serait « entérocoques ».
Résumé
Un TripleStore est une base de données qui stocke des informations sous forme de triples. Si le TripleStore est mis à disposition sur Internet, les utilisateurs peuvent envoyer des requêtes SPARQL au serveur via le web et obtenir ainsi toujours les données les plus récentes. Étant donné que tous les TripleStores utilisent la même structure pour stocker les informations, il est beaucoup plus facile de fusionner les données provenant de différentes sources.
Le lien avec Linked Data
La vision est très simple : de la même manière que les pages web sont reliées entre elles, nous pouvons relier entre elles des triples provenant de différents TripleStores. Cependant, la mise en œuvre de cette vision s’est avérée difficile au début et a nécessité une série de nouvelles idées.
Le défi
Reprenons les bactéries de l’exemple ci-dessus. Si l’on veut rassembler des informations provenant de plusieurs systèmes, il est important d’utiliser le même nom pour ces bactéries. Si chaque auteur utilise son propre nom ou sa propre orthographe (par ex. e.Coli, eColi, EColi), il n’est possible de décider qu’il s’agit de la même bactérie qu’au prix d’un effort manuel important.
Ce qui est recherché ..
Ce qui nous aiderait, c’est ce que l’on appelle un URI (Uniform Resource Identifier, en français : un identifiant unique pour une ressource). S’il existait un tel URI – et si nous l’appelions ici, dans l’exemple, de manière simplifiée, URI_ECOLI, chaque TripleStore contenant des informations sur cette bactérie pourrait ajouter un triple tel que
(e.Coli, URI, URI_ECOLI)
Avec cette nouvelle information, le nom interne e.Coli serait associé à l’ID unique au monde URI_ECOLI. Si un autre TripleStore gérait des informations sur cette bactérie sous le nom e-Coli et y établissait également le lien entre e-Coli et URI_ECOLI, il serait garanti qu’il s’agit du même sujet et les données pourraient être réunies (par exemple dans une requête SPARQL).
Une solution
Il existe désormais de très nombreuses approches pour générer des URI, la plus connue étant basée sur l’utilisation des informations de Wikipédia.
Déjà en 2007, dans le cadre d’un projet commun, le contenu de Wikipedia a été converti en un TripleStore et chacun de ces triples peut depuis être identifié par un URI. Par exemple, l’URI de la Haute école spécialisée bernoise est https://dbpedia.org/resource/Bern_University_of_Applied_Sciences[1]
S’il existe une entrée dans la dbpedia sur un thème donné, il est donc intéressant d’intégrer cet URI dans son TripleStore comme décrit ci-dessus et d’établir le lien avec d’autres TripleStores par ce biais.
Résumé
Pour transformer des données en données liées, il faut les enrichir à l’aide d’URI de manière à garantir que les données de différentes sources ont la même signification. Le TripleStore fournit la base technique, mais l’enrichissement des informations par des URI nécessite un travail manuel. Celui-ci est toutefois récompensé par la possibilité de relier les données entre elles de manière judicieuse.
Références
- Le Web sémantique pour l’ontologue de travail. Dean Allemang, James Hendler, Fabien Gandon, acm, 3ème édition, 2020
- Un guide du développeur pour le Web sémantique. Liyang Yu, Springer Verlag, 2016
- Le Web sémantique. Tim Berners-Lee, James Hendler, Ora Lassila, Scientific American, édition du 01.05.2001
- Site web : lindas.admin.ch
- Le site LinkedData de l’OFEV et des AFS
- Site web : visualize.admin.ch. Création de visualisations de données basées sur les données environnementales de Lindas
[1] L’URI indiqué ci-dessus adapte sa présentation au programme qui a envoyé la requête. Si l’URI est saisi dans un navigateur, on obtient les triples sous la forme d’une page HTML. Pour visualiser les triples « natifs » de la Haute école spécialisée bernoise, il faut un navigateur RDF ou le lien : https://dbpedia.org/data/Bern_University_of_Applied_Sciences.xml

![]() Markus Böhm est collaborateur scientifique pour la numérisation à l'Office fédéral de l'environnement (OFEV).
Markus Böhm est collaborateur scientifique pour la numérisation à l'Office fédéral de l'environnement (OFEV).






 Contributions en tant que RSS
Contributions en tant que RSS
Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !