How a Triplestore can publish data of the Swiss lakes

The Federal Office for the Environment (FOEN) uses a TripleStore database to publish environmental data on the Internet. This article shows which advantages such a technology can offer when building a network of environmental data.
In collaboration with the Federal Archives (SFA), the FOEN has put a TripleStore into operation at lindas.admin.ch and published the first environmental data there that can be queried with the help of SPARQL. If you want to go into less depth technically, you can independently convert the environmental data from Lindas into diagrams via the website visualize.admin.ch. Visualize accesses the triples stored in Lindas live via SPARQL.
As far as URIs are concerned, we are still at the beginning with the environmental data. Should other environmental organisations also use the TripleStore technology, the addition of URIs will only be a small step towards a comprehensive environmental data network. Many well-known tools and databases use tables as a basis for processing information. For example, to determine bathing water quality in lakes, the concentration of individual bacteria is measured. In tabular form, these measurements could be published as follows:

The structure chosen for this example seems intuitive – but was taken completely arbitrarily. It would be conceivable to
- omit the Unit column, as its value is always constant
- translate the names of the columns into English
- add more columns, such as the method of measurement or the location of the measuring device
There are no limits to creativity here. Unfortunately, this flexibility also makes it difficult to merge data from different sources.
Triples are a way of modelling information in a standardised way. For this purpose, the information is divided into three areas (hence the name triple):
- A Subject – the “topic” we want to say something about (e.g. the North Bath)
- A predicate (better property ) of the subject (e.g. the date on which a measurement was taken, and
- An object that contains the value of the property (e.g. 01.07.2022)
The collection of all information triples then forms the TripleStore database:
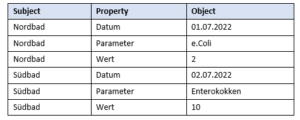
All TripleStores have exactly this structure – and even if this structure looks somewhat simple at first glance, it can already answer a number of interesting questions.
- Question: Which subjects are in the TripleStore?
- Answer: North bath, South bath
- Question: What properties does the subject Nordbad have?
- Answer: Date, parameter, value
- Question: Which parameters were measured?
- Answer: e.Coli, Enterococci
Without ever having to change the structure, more and more information can be added over time. With a new triple like (enterococci, category, bacteria), the object enterococci is now used as a subject and the new object bacteria is assigned to it via a property “category”. In this way, complex graphs are created that allow queries such as “Which bacteria were examined in the North Bath? “. Technically, the queries to the TripleStore are expressed in the SPARQL language. Consequently, triples are also used here. For example, the following pattern (Südbad, Parameter, ?) searches for all objects whose subject has the value “Südbad” and whose property has the value “Parameter”. In this case, the answer would be “enterococci”.
Summary
A TripleStore is a database that stores information in the form of triples. If the TripleStore is made available on the internet, users can send SPARQL queries to the server via the web and always receive the most up-to-date data. Since all TripleStores use the same structure to store information, data from different sources can be merged much more easily.
The connection to Linked Data
The vision is very simple: just as web pages are linked together, we can link triples from different TripleStores together. However, the implementation of this vision was difficult at the beginning and required a number of new ideas.
The challenge
Let’s take the bacteria from the example above again. If one wants to combine information from several systems, it is important that the same name is used for these bacteria. If each author uses a different name or spelling (e.g. e.Coli, eColi, EColi), it is only possible to decide with a great deal of manual effort that the same bacterium is meant here.
What we are looking for is ..
What would help us is a so-called URI (Uniform Resource Identifier). If such a URI existed – and let’s call it URI_ECOLI in the simplified example here – then every TripleStore that contains information about this bacterium could add a triple like:
(e.Coli, URI, URI_ECOLI)
With this new information, the internal name e.Coli is linked to the globally unique ID URI_ECOLI. If another TripleStore were to manage information on this bacterium under the name e-Coli and also establish the link between e-Coli and URI_ECOLI there, it is ensured that the topic is the same and the data can be merged (e.g. in a SPARQL query).
A solution
There are now very many approaches to generating URIs, the best known being based on the use of information from Wikipedia.
As early as 2007, the content of Wikipedia was converted into a TripleStore in a joint project, and since then each of these triples can be identified via a URI. For example, the URI of the Bern University of Applied Sciences is https://dbpedia.org/resource/Bern_University_of_Applied_Sciences[1]
So if there is an entry on a topic in the dbpedia, it makes sense to include this URI in one’s TripleStore as described above and to use it to establish the connection to other TripleStores.
Summary
To convert data into linked data, it must be enriched with the help of URIs in such a way that it can be ensured that data from different sources have the same meaning. The TripleStore provides the technical basis, but adding URIs to the information requires manual work. However, this is rewarded by the possibility of linking data in a meaningful way.
References
- Semantic Web for the Working Ontologist. Dean Allemang, James Hendler, Fabien Gandon, acm, 3rd Edition, 2020
- A Developer’s Guide to the Semantic Web. Liyang Yu, Springer Verlag, 2016
- The Semantic Web. Tim Berners-Lee, James Hendler, Ora Lassila, Scientific American, issue of 01.05.2001
- Website: lindas.admin.ch
- The LinkedData website of the FOEN and the SFA
- Website: visualize.admin.ch. Creating data visualisations based on the environmental data from Lindas
[1] The above URI adapts its representation to the programme that sent the request. If you enter the URI in a browser, you will get the triples in the form of an HTML page. To view the “native” triples of the Bern University of Applied Sciences, you need an RDF browser, alternatively the link: https://dbpedia.org/data/Bern_University_of_Applied_Sciences.xml

![]() Markus Böhm is the Scientific Assistant for Digitalisation at the Swiss Federal Office for the Environment (FOEN).
Markus Böhm is the Scientific Assistant for Digitalisation at the Swiss Federal Office for the Environment (FOEN).
 Contributions as RSS
Contributions as RSS Comments as RSS
Comments as RSS
Leave a Reply
Want to join the discussion?Feel free to contribute!