Mit KI verstehen, wie uns Medieninhalte beeinflussen

Zeitungsinhalte können aufgrund ihrer Polarität die Denkweise oder die Stimmung der Menschen verändern. Deshalb ist es wichtig, ihre Bedeutung zu verstehen. Kann maschinelles Lernen uns helfen und die Stimmung für uns vorhersagen? Unser Autor hat diese Frage in seiner Bachelorarbeit untersucht.
Mit Hilfe der Sentimentanalyse oder des Opinion Mining lässt sich die Polarität oder Stärke der Meinung (positiv oder negativ), die in einem geschriebenen Text zum Ausdruck kommt, herausfinden [1]. Oft werden solche Technologien in der Wirtschaft eingesetzt, um die soziale Stimmung für ihre Marke, ein bestimmtes Produkt oder eine Dienstleistung zu verstehen, insbesondere in den folgenden zwei Anwendungsfällen:
- Kundenklassifizierung: Mit Hilfe der Stimmungsanalyse können Kunden nach ihrer emotionalen Stimmung klassifiziert werden. Dies bietet die Möglichkeit, Kunden zu finden, die eine höhere Kaufbereitschaft aufweisen.
- Produktklassifizierung: Bewertung, wie ein Produkt auf dem Markt wahrgenommen wird, basierend auf Online-Bewertungen.
- Chatbot-Training: Mit den Ergebnissen eines Stimmungsanalyse-Tools ist es möglich, Chatbots zu trainieren, um bestimmte Kundenstimmungen zu erkennen und darauf zu reagieren.
Mit einem höheren Grad an Skalierbarkeit und Automatisierung in den meisten aktuellen Anwendungen lassen sich solche Tools zur Stimmungsanalyse leicht erweitern oder in ein automatisiertes System integrieren. Hinter den Kulissen ist die Stimmungsanalyse eine spezielle Form des maschinellen Lernens, bei der häufig Text- oder Audiospuren als Trainingsdaten verwendet werden. Sentiment Analysis kann auch auf Texte wie Nachrichtenartikel angewendet werden [2]. Meine Bachelorarbeit [3] basierte auf der Erstellung eines maschinellen Lernmodells, um eine Stimmungsanalyse für Schweizer Zeitungen durchzuführen. Die Idee war, ein Modell zu erstellen, zu trainieren, anzupassen und zu verbessern, so dass es geeignet ist, verschiedene Schweizer Zeitungen zu analysieren und zu bestimmen, welche Zeitungen mit den meisten negativen und positiven Einstellungen geschrieben werden.
Trainieren eines maschinellen Lernmodells
Um dieses Modell zu erstellen, wurden mehrere moderne Tools (wie Tensorflow, Keras und Ktrain) verwendet, und insbesondere wurde ein vortrainiertes Sprachmodell auf der Grundlage des BERT-Modells von Google [4] eingesetzt. Solche vortrainierten Sprachmodelle verfügen über ein grundlegendes Verständnis der Sprache und werden dann mit zusätzlichen Datensätzen für einen bestimmten Zweck trainiert, z. B. für die Stimmungsanalyse. Für das Training des maschinellen Lernsystems wurden verschiedene Datensätze verwendet, die auf vorhandenen positiven und negativen Texten basieren. Jeder Datensatz hatte eine Vorverarbeitungsphase, um die Daten für das Training vorzubereiten. Abbildung 1 zeigt die detaillierte Systempipeline der in diesem Projekt verwendeten Datenverarbeitung.  Abbildung 1: Die in diesem Projekt verwendete Systemarchitektur, die das maschinelle Lerntraining und die Datenerfassung umfasst. Als Trainingsdaten wurde ein bestehender Datensatz mit deutschen Filmkritiken verwendet (Filmstarts-Datensatz aus [5]). Unter Verwendung des vortrainierten BERT-Modells und dieses Datensatzes wurde eine Genauigkeit von 93% erreicht.
Abbildung 1: Die in diesem Projekt verwendete Systemarchitektur, die das maschinelle Lerntraining und die Datenerfassung umfasst. Als Trainingsdaten wurde ein bestehender Datensatz mit deutschen Filmkritiken verwendet (Filmstarts-Datensatz aus [5]). Unter Verwendung des vortrainierten BERT-Modells und dieses Datensatzes wurde eine Genauigkeit von 93% erreicht.
Analyse von Schweizer Zeitungen
Mit diesem Modell für maschinelles Lernen wurden Zeitungsartikel aus der Schweiz analysiert. Das Modell kann man sich im Grunde als eine Funktion vorstellen, die einen beliebigen Text als Eingabe annimmt, ihn auswertet und in negativ und positiv klassifiziert. Mit Hilfe zweier bestehender Webservices (APIs), die Zugang zu Nachrichtenartikeln bieten, habe ich regelmäßig neue Artikel gesammelt und sie nach ihrer Stimmung klassifiziert. Dies ermöglichte dann eine aggregierte Visualisierung der Stimmung in der Nachrichtenlandschaft der Schweiz, sortiert nach Thema oder Nachrichtenanbieter. Das Diagramm in Abbildung 2 beschreibt den prozentualen Anteil der positiven und negativen Stimmung aller Artikel, die ich erhalten habe. Die y-Achse beschreibt den prozentualen Anteil aller Artikel mit positiver oder negativer Stimmung, die sich auf der x-Achse befinden. Es ist zu erkennen, dass insgesamt fast 60 % der Artikel mit einem negativen Sentiment eingestuft wurden. 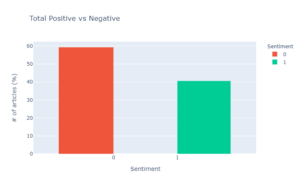 Abbildung 2 Gesamtklassifizierung der Stimmung der gesammelten Artikel. Das Diagramm in Abbildung 3 gibt einen Überblick über die Positivität und Negativität der verschiedenen Themen.
Abbildung 2 Gesamtklassifizierung der Stimmung der gesammelten Artikel. Das Diagramm in Abbildung 3 gibt einen Überblick über die Positivität und Negativität der verschiedenen Themen. 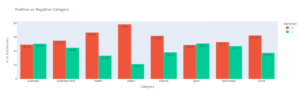 Abb. 3 Positivität und Negativität pro Nachrichtenthema. Wir haben festgestellt, dass Themen wie Gesundheit oder Wissenschaft eine Mehrheit negativer Artikel aufweisen. Dies ist nicht überraschend, da die Artikel im Mai 2021, mitten in der Pandemie, gesammelt wurden. Die Themen Wirtschaft und Sport sind etwas positiver; wir können jedoch schlussfolgern, dass wir beim Lesen der üblichen Schweizer Zeitungen eher negativen Nachrichten ausgesetzt sind.
Abb. 3 Positivität und Negativität pro Nachrichtenthema. Wir haben festgestellt, dass Themen wie Gesundheit oder Wissenschaft eine Mehrheit negativer Artikel aufweisen. Dies ist nicht überraschend, da die Artikel im Mai 2021, mitten in der Pandemie, gesammelt wurden. Die Themen Wirtschaft und Sport sind etwas positiver; wir können jedoch schlussfolgern, dass wir beim Lesen der üblichen Schweizer Zeitungen eher negativen Nachrichten ausgesetzt sind.
Fazit
Die Zeitungen von heute haben die Macht, die gesamte Sichtweise auf die Welt zu prägen. Eine positive oder negative Einstellung kann unsere Stimmung beeinflussen, wenn wir sie täglich lesen. Unsere Studie ergab, dass die Mehrheit der Nachrichtenartikel in der Schweiz als negativ eingestuft werden kann. Diese interessante Erkenntnis könnte künftige Forschungen auf dem Gebiet der Sozialpsychologie anregen, um die Auswirkungen auf die Gesellschaft weiter zu untersuchen.
Referenzen
- Cambria, E., Das, D., Bandyopadhyay, S., & Feraco, A. (Eds.). (2017). A practical guide to sentiment analysis (pp. 1-196). Cham, Switzerland: Springer International Publishing.
- Balahur, A., Steinberger, R., Kabadjov, M., Zavarella, V., van der Goot, E., Halkia, M., … & Belyaeva, J. (2010, Mai). Sentiment Analysis in the News. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10).
- Girgio Bakhiet Derias (2021). Sentiment-Analyse auf Schweizer Zeitungen. Bachelor Thesis. Berner Fachhochschule, Switzerlad.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, Januar). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT (1).
- Guhr, O., Schumann, A. K., Bahrmann, F., & Böhme, H. J. (2020, Mai). Training eines flächendeckenden deutschen Sentiment-Klassifikationsmodells für Dialogsysteme. In Proceedings of the 12th Language Resources and Evaluation Conference (S. 1627-1632).

![]() Giorgio Bakhiet Derias schloss 2021 den Bachelorstudiengang Informatik an der Berner Fachhochschule ab, mit einer Spezialisierung in Data Engineering. Jetzt ist er Praktikant im Projektmanagement bei der SBB.
Giorgio Bakhiet Derias schloss 2021 den Bachelorstudiengang Informatik an der Berner Fachhochschule ab, mit einer Spezialisierung in Data Engineering. Jetzt ist er Praktikant im Projektmanagement bei der SBB.



 Beiträge als RSS
Beiträge als RSS
Dein Kommentar
An Diskussion beteiligen?Hinterlasse uns Deinen Kommentar!