How Wikidata Is Solving Its Chicken-or-Egg-Problem in the Field of Cultural Heritage
On 29 October 2018, Wikidata turned six. What was at its launch a fledgling project is today inspiring numerous people with new and surprising ideas about what could be achieved in a linked data world. In this article we will give a brief overview of how Wikidata is used in the heritage sector and how the community is doing in addressing the egg-and-hen-problem of linked open data.
Over the past years, a growing community has formed on Wikidata around heritage data. Its members are ingesting, cleansing and improving data; discussing data modelling issues; contacting new data providers and developing applications based on Wikidata. Their vision is for Wikidata to become a central hub for data integration, data enhancement and data management in the cultural heritage domain. According to the group’s mission statement, this includes:
- “establishing Wikidata as a database that covers the entire world’s cultural heritage;
- establishing Wikidata as a central hub that interlinks [heritage] collections around the world and provides links to bibliographic, genealogical, scientific and other collections of information and thereby functions as the ultimate authority file providing mapping information between these different collections;
- fostering truly multilingual and global collaboration around the description and management of heritage data among people from various backgrounds;
- leveraging synergies between institutions, helping them to reduce duplicate work;
- encouraging debate in the community by highlighting and interrogating differences in perspective; and
- providing a single source of data for some of the most popular web sites and apps, including Wikipedia infoboxes and lists” (Wikiproject Cultural heritage).”
As the last point makes it clear, the actual usefulness of the data comes with its use. Either in the form of services that are targeted at end users or by providing insights that are turned into stories that can be shared. To create a flourishing ecosystem of Wikidata-based applications running on high-quality data, a critical chicken-or-egg problem needs to be overcome: without complete and high-quality data, there are no cool apps. But without interesting apps, there are few incentives to provide data and to improve its quality. In other words: the main drivers of data quality and completeness are interesting and widely used applications, while the motivation to develop good apps is far greater if they can build upon a high-quality and complete data bases. In this article we will present a few of the things the Wikidata community is doing to address its chicken-or-egg problem.
Data Use in Wikipedia and other Wikimedia Projects
One of the basic ideas behind Wikidata was to create a central repository of structured data for Wikimedia projects, such as the free online-encyclopedia Wikipedia, Wikimedia Commons, and others. The immediate use of Wikidata in the context of Wikipedia can take the form of infoboxes or lists. An example of a Wikidata-powered infobox can be found in the Wikipedia article on Ferdinand de Saussure; it features an image and structured data that are partly pulled from Wikidata. An example of a Wikidata-powered list can be found in the Portuguese article about paintings by Alfredo Norfini.
Such infoboxes and lists are an immensely useful tool to eliminate the duplication of efforts across Wikipedia’s different language communities, as the data can be curated in a central database. At the same time, they have a large impact in terms of visibility of the data thanks to the prominence of Wikipedia on the Internet. Yet, some of the largest communities, such as the German or the English Wikipedia communities, which could generate substantial spill-overs into smaller language communities, have so far shown the biggest restraint when it comes to taking up Wikidata-powered infoboxes and lists on a broader scale. The arguments brought forward have mostly been related to data quality or to the fear of an exacerbation of the vandalism problem. Vandalism could indeed be encouraged by the high visibility of the centrally managed data and it might be difficult to counteract data manipulations. Many communities have indeed long questioned the adequacy of Wikidata’s edit tracking tools, which has triggered the improvement of these tools over the years. Some members of non-English communities may in addition feel uneasy about having to curate data on the Wikidata platform, which involves taking part in community discussions that predominantly take place in English. Furthermore, larger communities may expect fewer benefits from Wikidata than smaller communities, as they have already quite good data coverage in many areas thanks to established methods of data curation that were developed prior to the introduction of Wikidata.
On the other end of the spectrum, some of the smaller (or medium-sized) language communities, such as the Catalan Wikipedia, have been pioneers in this area, creating infobox templates with interactive maps, detailed career information for biographies and various other information directly fetched from Wikidata. In fact, in fall 2017 the Catalan community announced that over 50% of the 550’000 articles on Catalan Wikipedia were using data from Wikidata.
In addition to the direct inclusion of data from Wikidata in Wikipedia articles, Wikidata has also been used as a basis for the automatic generation of article stubs that could then be extended by Wikipedia editors. This approach is especially useful for harmonizing the structure of articles in specific areas. One of the tools for this is the “Mbabel Article Generator”, which was first developed for a New-York-based project, about museums, and was then extended by a Brazilian team to other classes of subjects, such as works of art, books, films, earthquakes, and journals. Here again, a Wikidata-based tool can help reduce the workload of Wikipedians by using centrally curated data that can be applied across language communities. Another tool that serves a similar purpose for biographical articles is “PrepBio”.
Data Use Beyond the Wiki-World
The use of Wikidata is not confined to Wikimedia projects alone. Here are few examples of uses of Wikidata outside the realm of the Wiki-world:
- Points of interest. One prominent application is “Monumental”, a Wikidata-based web app which displays information related to historical monuments on a map. The app allows logged-in users to directly edit Wikidata and includes a Wikidata game for the matching of Wikidata entries with Wikimedia Commons categories. The app is used as part of “Wiki Loves Monuments” – the world’s largest photo competition. This contest has been accompanied by an effort to gather monument-related data in a centralized database which pre-dates Wikidata. This explains why the app has been able to provide good coverage of historical monuments for numerous countries. Monuments data is also used by “Panandâ”, a mobile app for the exploration of the cultural heritage of the Philippines based on the historical markers and commemorative plaques installed by the National Historical Commission. These types of apps could in the future be adapted to other areas where objects of interest are displayed on a map, e.g. museums, water-fountains, public artworks, cultural venues, etc.

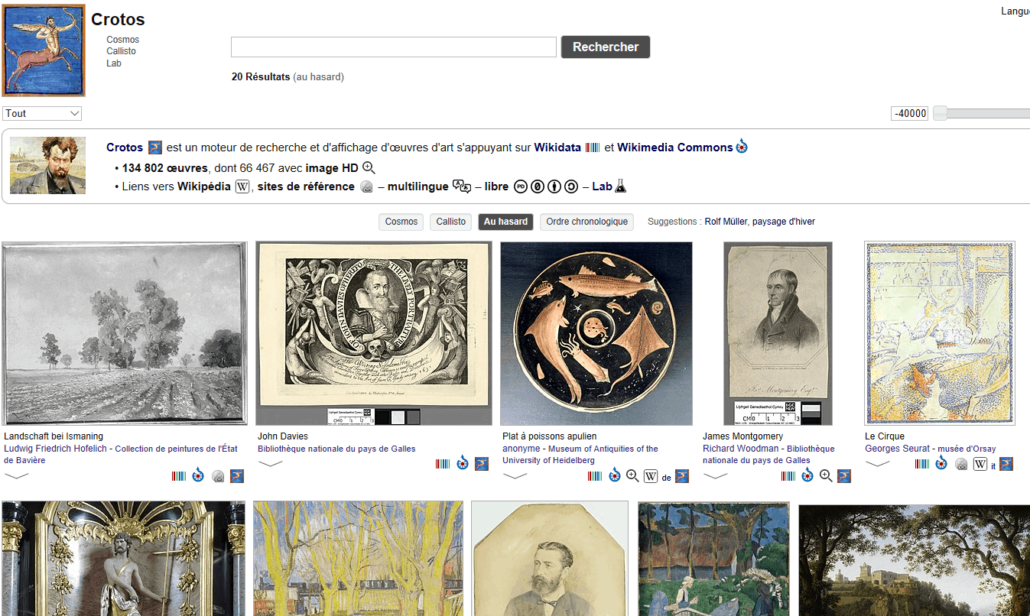
- Visual art. Another app that has been around for a while is “Crotos”. It builds upon the “Sum of All Paintings Project”, the first Wikidata project to clearly announce the goal of gathering data about all the cultural heritage of a specific kind. It provides a search and display engine for visual artworks, based on Wikidata and using Wikimedia Commons files. Search results can be filtered using work categories and time periods. Artworks can be displayed in random or chronological order. Like in Monumental, there is a contribution mode, which allows works with missing properties to be filtered, so that the information can be completed by the user.
- Bibliographic data. Yet another area of cultural heritage is covered by “Scholia”, a web app that presents bibliographic information and scholarly profiles of authors and institutions using Wikidata. It is being developed in the framework of the larger WikiCite initiative, which seeks to index bibliographic metadata in Wikidata about resources that can be used to substantiate claims made on Wikidata, Wikipedia or elsewhere. While its intended scope is equally comprehensive as for the two previous examples, work is still at an early stage and Scholia is therefore biased due to its fragmentary data basis.
- Thematic timelines. The most well-known application here is “Histropedia”, which uses data from Wikipedia and Wikidata to automatically generate interactive timelines with events linked to Wikipedia articles. Users can combine timelines and events to create their own custom timelines. The web app “Tempo-spatial display” adds another dimension by combining chronological and geographic information on a specific topic, including a timeline of events and a map.

- New forms of access to heritage collections. Several applications help us explore heritage collections, such as “Collection Explorer” which focuses on a specific institution, “Manuscript Explorer” and “Astrolabe Explorer”, which focus on specific thematic areas or an app exploring the Sibthorp & Bauer Expedition and subsequent book: the Flora Greaca, a book full of beautiful illustrations which can be viewed via the app. Further applications provide new ways of access heritage collections: “Textes d’affiches” is a web app that links movie posters with the artistic works they are based on. It points users who are more familiar with the movies to the library content in the form of full-texts on the online platform of the National Library of France, and so giving film buffs more material for dinner party conversations! “Cultural History Baseball Cards” in turn allows users to navigate through both scholarly and cultural materials related to the players, managers, and executives who have shaped the game’s history. The number of other areas these applications could be adapted to is almost limitless.

- Networks of people. The application “Ancient intellectual network” provides a visualization of the relationships between master and student from Socrates to the end of the Hellenistic period. There are also a few tools that can be used to visualize family trees and relationships, such as the “Ancestors Tool” and “GeneaWiki”. A network visualization feature has also been implemented on “Scholia”, covering current academic networks. Similar applications could be imagined for other types of relationships between people.
- Collaborative cataloguing. A particularly interesting application is “Inventaire”, which caters to its own community of users who provide information about the books in their private collections, including the information under which conditions the books can be borrowed. This service is based on Wikidata and provides an excellent example how to exploit the symbiosis between a smaller community and Wikidata at large. The users of Inventaire are contributing to an ever-growing catalogue of books that is automatically integrated with the data from library catalogues that are amassed in Wikidata.

- Wikidata as an authority file. As “Text razor“ demonstrates, Wikidata’s knowledge graph can be used for entity extraction (named entity recognition) and content categorization. In fact, Wikidata is playing more and more the role of an authority file by complementing long-established authority files from the heritage field, such as VIAF or GND, which are instrumental in disambiguating and interlinking entries in library catalogues and archival finding aids.





Concluding Remarks
As this article has shown, there is already a variety of Wikidata showcase applications in the field of cultural heritage, and activities to resolve Wikidata’s chicken-or-egg problem are well under way. As the examples also demonstrate, more efforts are needed to improve data quality and completeness. Most promising from this point of view are applications that are linked to campaigns to improve the underlying data, such as Monumental, or applications that encourage data provision and enhancement by community members, such as Inventaire or the use of Wikidata in Wikipedia. We can only hope that a positive feedback loop ensues from these first Wikidata-based applications, and that we will see many more and better apps in the future, along with concerted efforts to enhance the quality and completeness of the data – the prerequisites of exciting applications!
References
- “Wikidata, a rapidly growing global hub, turns five” (blog post by Andrew Lih and Robert Fernandez, 30 October 2017).

![]() Beat Estermann ist stellvertretender Leiter des Instituts Public Sector Transformation der BFH Wirtschaft, wo er die Fachgruppe “Daten & Infrastruktur” koordiniert. Mit Fragen rund um Linked Open Data beschäftigt er sich seit mehreren Jahren im Rahmen von Forschungsprojekten und Beratungsmandaten im Auftrag von Behörden, Gedächtnis- und Kulturinstitutionen.
Beat Estermann ist stellvertretender Leiter des Instituts Public Sector Transformation der BFH Wirtschaft, wo er die Fachgruppe “Daten & Infrastruktur” koordiniert. Mit Fragen rund um Linked Open Data beschäftigt er sich seit mehreren Jahren im Rahmen von Forschungsprojekten und Beratungsmandaten im Auftrag von Behörden, Gedächtnis- und Kulturinstitutionen.

 Beiträge als RSS
Beiträge als RSS
Call for Project Proposals:
The “My-D Foundation” is addressing the “hen-and-egg” problem in the field of linked open data by supporting projects that feature interdisciplinary showcase applications along with concerted efforts to improve the data basis the applications build on. Its first call for projects focuses on the intersection of Wikidata and other public sources of data (e.g. OGD). Project proposals in English can be submitted until 31 January 2019 to application@my-d.org.
Source: https://www.my-d.org/index.php/www-my-d-org/projects