Wann lohnt sich Entity Extraction?

Ergebnisse einer Masterarbeit zur automatischen Entity-Extraction bei der Schweizerischen Theatersammlung
Die Digitalisierung schreitet voran und betrifft immer mehr Lebenssphären, Branchen und Institutionen. Archivinstitutionen in der Schweiz beobachten diese Entwicklung mit grossem Interesse und sind auf dem Weg, sich in diesem Kontext neu zu positionieren. Auch intern wird versucht, Effizienzsteigerungen mit den neuen Ansätzen zu erzielen, wie das Beispiel der Schweizerischen Theatersammlung zeigt. Seit Kurzem wurde dort in Zusammenarbeit mit der BFH Wirtschaft ein neues Datenerfassungskonzept entwickelt und im Rahmen einer Machbarkeitsstudie überprüft. In diesem Beitrag wird auf die Eckpunkte der durchgeführten Studie eingegangen.
Logo der Schweizerischen Theatersammlung
Die Schweizerische Theatersammlung ist eine zentrale Archivierungsstelle für sämtliche Dokumente zum Schweizer Sprech-, Musik und Tanztheater. Sie archiviert Dokumente, die vor, während und nach der Produktion entstehen und besitzt die grösste Fachbibliothek der Schweiz mit Büchern, Periodika, Stücktexten etc. Die im Archiv vorhandenen Materialien sind elektronisch mit Inszenierung-Datenbanken erschlossen, welche detaillierte Informationen zu Produktionen der Schweizer Theater auf elektronischem Wege liefern.
Nun eine Frage: Wie stellen Sie sich die regelmässige Datenerfassung von hunderten verschiedensten Insitutionen, klein und gross, professionell oder amateur, an zentraler oder (viel) weniger zentraler Lage vor?
Wenn diese Frage immer noch nicht kompliziert genug ist, muss noch erwähnt werden, dass die Theater nicht gesetzlich dazu verpflichtet sind, Informationen der Theatersammlung zur Verfügung zu stellen und es wurden dafür keine elektronischen Mechanismen vorgesehen. Wie üblich werden solche komplexe Situationen durch minutiöse manuelle Arbeit gehandhabt. Im Falle der Theatersammlung bedeutet dies, dass die Produktionen, schon seit mehr als 20 Jahren, aus öffentlich vorhandenen Materialien (wie z.B. Jahresprogramme und Programmhefte der Theater) in die Inszenierungs-Datenbanken abgetippt werden. Sollte es keine modernere Alternative geben, fragen Sie? Genau diese Frage hat sich vor Kurzem die Theatersammlung gestellt und die Antwort ist natürlich „Ja, es gibt mehrere“.
Eine potentielle Alternative wäre Entity Extraction, dank welcher die relevanten Metainformationen zu archivierten Premieren durch Software automatisch erkannt werden können. In diesem Fall übernimmt die Software sozusagen das manuelle Eintippen und lässt den Menschen lediglich die Kontrollfunktion geniessen und ein paar wenige Fehler korrigieren. Voller Enthusiasmus machte ich mich gemeinsam mit dem Auftraggeber an die Arbeit. Wir stellten zu unserer Zufriedenheit fest, dass es bereits erfolgreiche Implementationen von Entity Extraction gibt. Ausgerüstet mit einem passenden Software-Framework (General Architecture for Software Engineering GATE (1) ) stiegen wir in die Machbarkeitsanalyse ein.
Es wurden manuell 804 Entitäten annotiert, dutzende von Exktraktionsregeln definiert und das Framework zur Auswertung der Ergebnisse gebastelt. Nach mehreren Wochen Einarbeitung und effektiver Software-Entwicklung waren die erste Ergebnisse da. Und sie überzeugten uns… zu wenig. Davon ist die zweite Iteration entstanden, wo Konsequenzen der ersten Iteration gezogen und die notwendigen Verbesserungen angestrebt wurden. Nach der Verfeinerung der Extraktionsregel in der zweiten Iteration wurde die Gesamtquote von 52.86% erreicht, d.h. aus 804 manuell annotierten Entiäten konnte die Software 425 Entitäten automatisch erkennen. Anders gesagt, entsteht mit dem Einsatz der Entity Extraction bei der Theamtersammlung ein Effizienzgewinn von ca. 365 Personenstunden pro Jahr. In absoluten Zahlen tönt dieses Ergebnis ziemlich vielversprechend. So wurde die Machbarkeit der Lösung bestätigt, der Gewinn quantifiziert und die Ziele der Untersuchung erreicht.
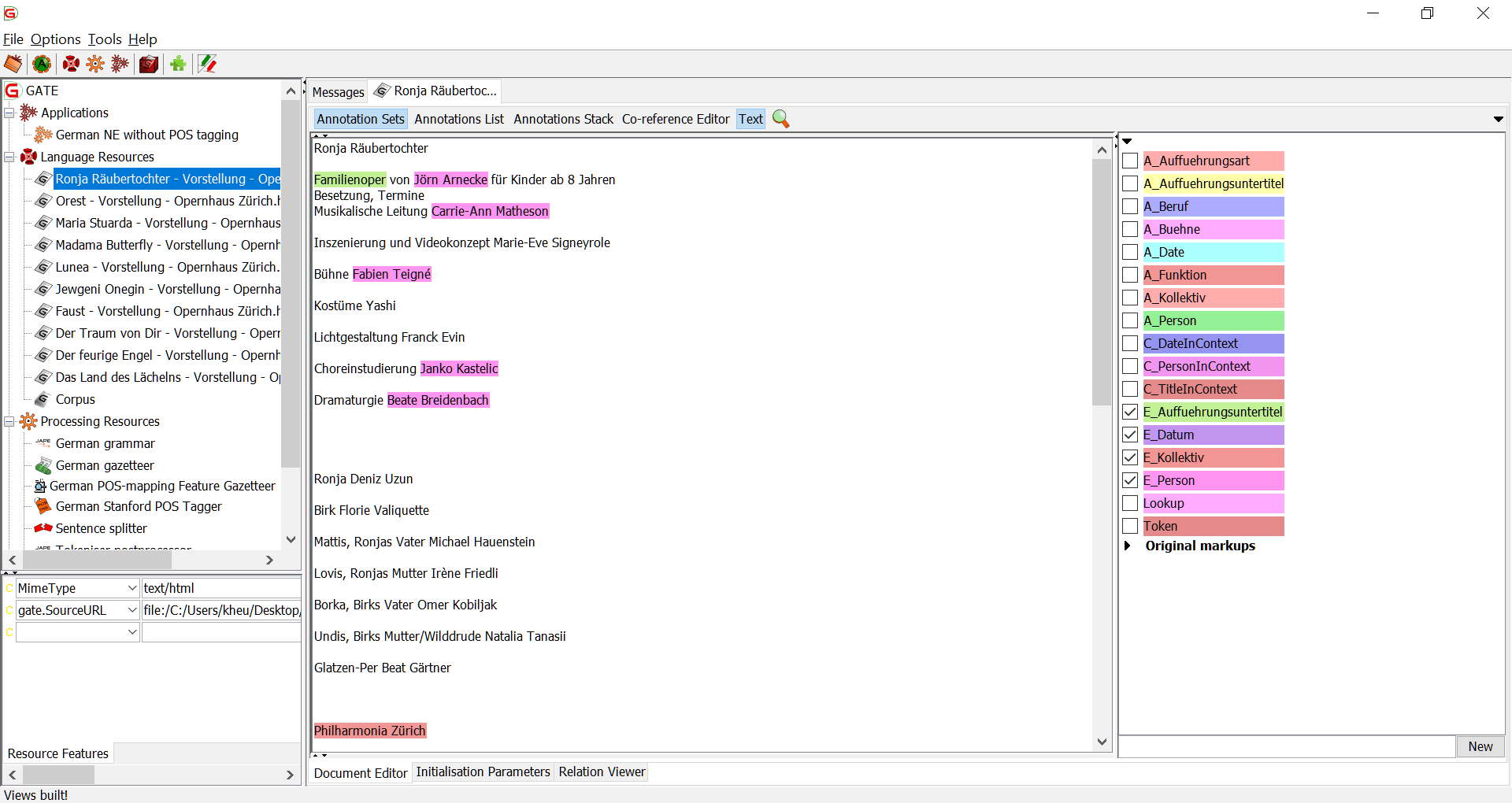
Ein Beispiel des Dokumentes mit erkannten Entitäten (Graphische Oberfläche vom GATE-Framework)
Trotz der erfolgreichen Machbarkeitsstudie wird der untersuchte Ansatz bei der Theatersammlung nicht weiter verfolgt.
Es hat sich im Rahmen der Machbarkeitsstudie herausgestellt, dass im Verhältnis zu den Aufwänden für die Definition und die Weiterentwicklung der Extraktionsregeln unbedeutende oder gar keine Einsparungen anfallen. Die Gründe dafür lassen sich potentiell auf andere ähnliche Institutionen übertragen und sind wie folgt:
- Hohe Erkennungsquoten und wenige falsch-positive Ergebnisse zugleich sind mit möglichst präzisen Extraktionsregeln zu erreichen, welche hohe Aufwände verursachen.
- Die begriffliche, semantische und gestalterische Vielfalt der untersuchten Dokumente macht die Erstellung der generischen und zugleich präzisen Extraktionsregeln fast unmöglich. So hätten die Regeln praktisch für jedes Theaterhaus verfeinert werden müssen, was die Aufwände erhöht und eine Steigerung der Komplexität der Lösung mit sich bringt.
- Masseneffekte für die bedeutenden Effizienzsteigerungen waren nicht vorhanden. Tatsächlich werden bei der Theatersammlung pro Jahr lediglich ca. 1700 Datensätze erfasst, was im Falle grosser Investitionen wenig ist.
Mit anderen Worten: Entity Extraction lohnt sich am besten dann, wenn viele ähnliche Dokumente nach generischen Regeln verarbeitet werden müssen. Wie erwähnt ist das bei der Theatersammlung leider nicht der Fall. Anstatt Entity Extraction wurde deshalb der Theatersammlung empfohlen, die Verarbeitung der internen Rohdaten von Theaterhäusern zu untersuchen. Diese Daten könnten in die Inszenierung-Datenbank mit potentiell wenigen Anpassungen periodisch übernommen werden. Damit wäre die Umwandlung der Rohdaten in Publikationen, aus welchen wiederum Rohdaten nach komplexen Regeln abgeleitet werden, umgangen und die unnötige Komplexität wäre vermieden.

![]() Business Analyst at SBB CFF FFS, Master in Wirtschaftsinformatik an der Berner Fachhochschule BFH (eugene.khoroshutin@gmail.com)
Business Analyst at SBB CFF FFS, Master in Wirtschaftsinformatik an der Berner Fachhochschule BFH (eugene.khoroshutin@gmail.com)
 Beiträge als RSS
Beiträge als RSS
Dein Kommentar
An Diskussion beteiligen?Hinterlasse uns Deinen Kommentar!